Discover Sample Datasets
Human

Pool up to 96 samples per library while retaining full-transcript information.
Differential gene expression, splicing variants and isoform detection.
Process cells directly in-well using optimized lysis buffer.
Generate sequencing-ready libraries from cells in a single working day.
Built for teams requiring high-throughput detection of full-length coding transcripts, isoforms, and splice variants in 2D cell lines and primary cells without RNA extraction. Ideal for studies with larger cohorts, more conditions, or more timepoints than possible to assess with standard bulk mRNA-seq methods.
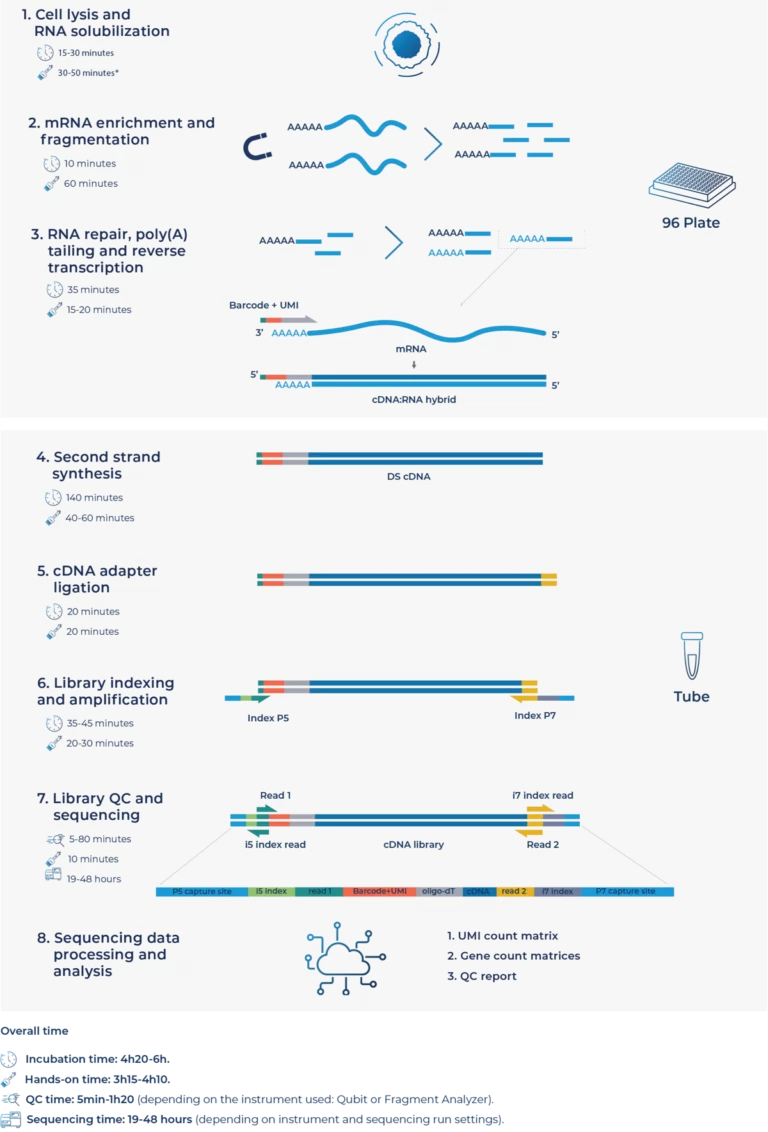
MERCURIUS™ Full-Length DRUG-seq enables bulk mRNA-seq at scale through in-well lysis, early barcoding, and multiplexing of up to 96 samples in a single tube in a one-day workflow. It provides full-length transcript coverage of coding transcripts without compromising depth, data quality, or sensitivity compared to sample-by-sample methods. It enables high-throughput mRNA-seq on Illumina® and AVITI™ platforms.
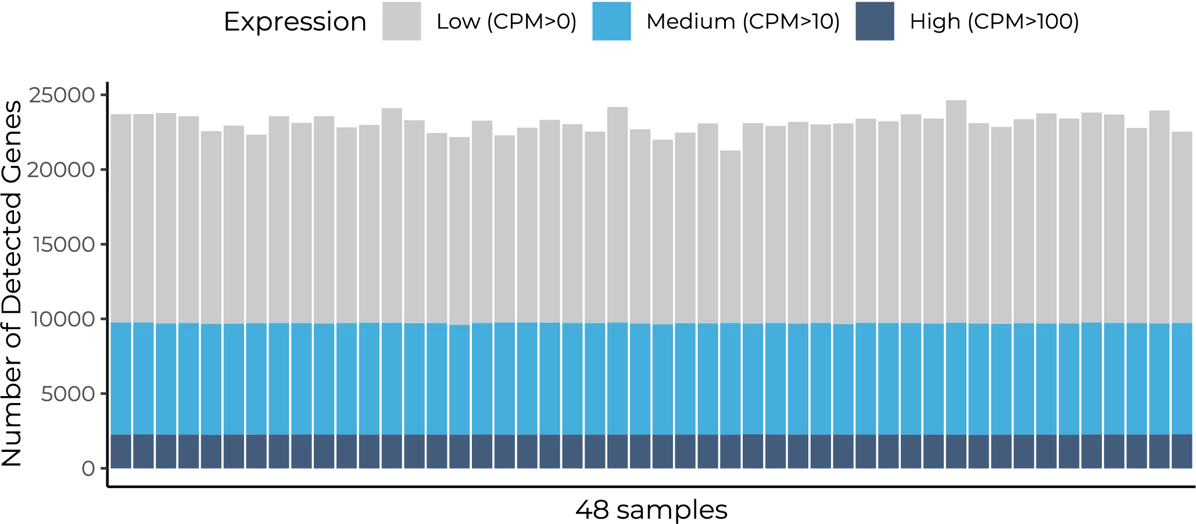
Distribution of the number of detected genes across 48 samples prepared with the MERCURIUS™ Full-Length BRB-seq service. The library was sequenced at an average of 12 million reads.

Full-Length BRB-seq performance shows 99% demultiplexing rate from raw data, 78% mapping rate, and 18% duplication rate of the 48 pooled samples and sequenced at 12 million reads per sample.
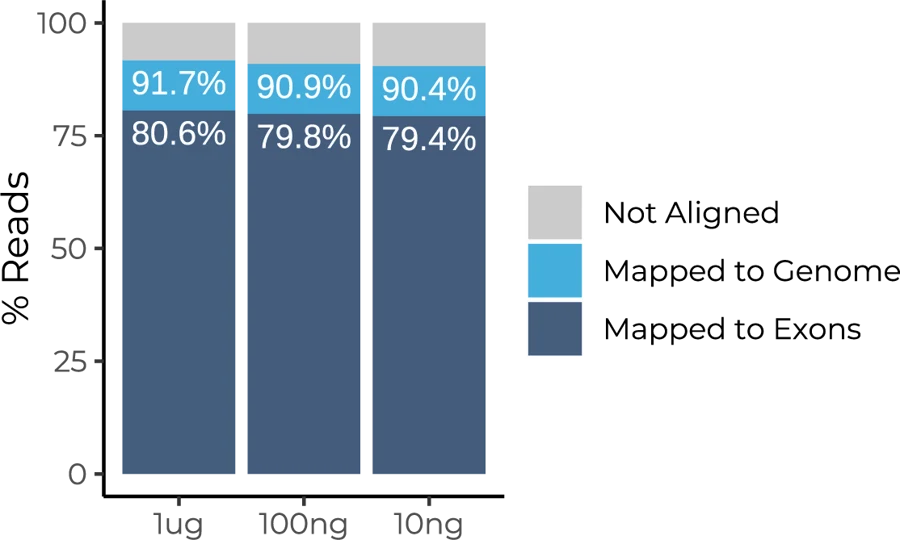
Mapping rates are uniform across three RNA inputs tested: 1ug, 10ng, and 100ng. Human Universal Reference RNA was used to prepare mRNA Full-Length BRB libraries.
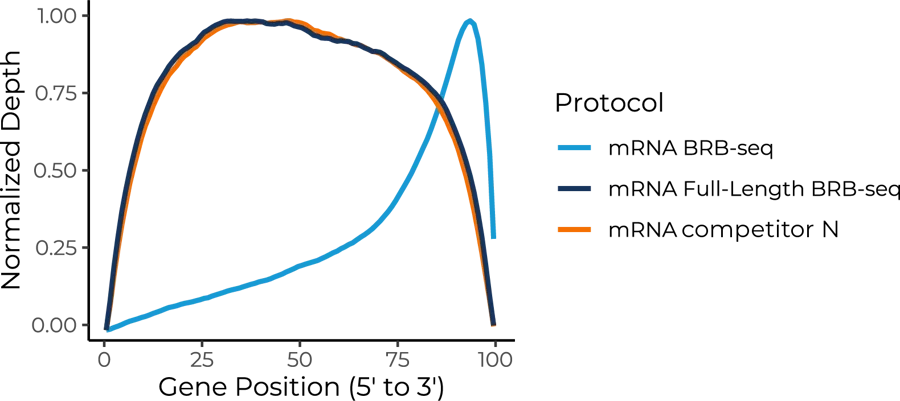
The gene body coverage shows a consistent and uniform reads distribution across the entire gene body for the Full-Length BRB-seq protocol, comparable to competitor N protocol, while the BRB-seq protocol shows a significant 3′ bias due to its poly-A selection methodology.
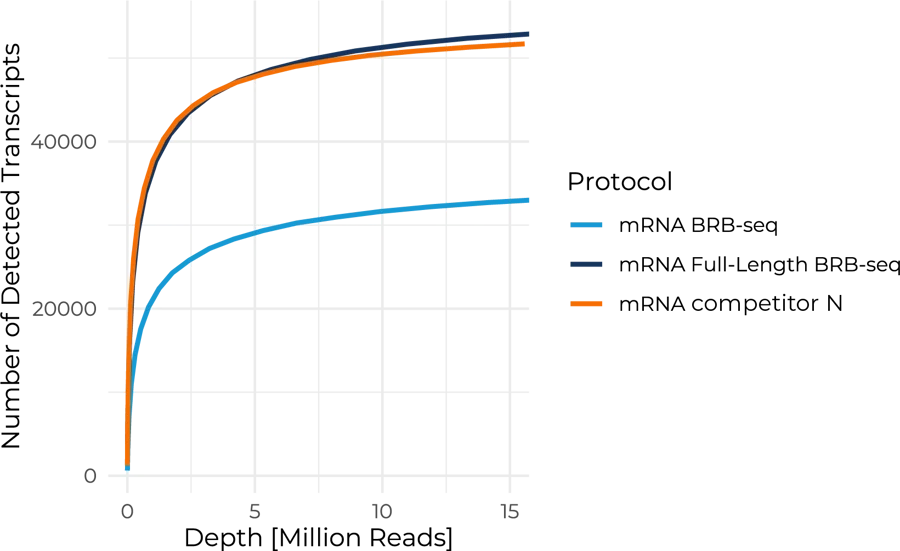
Benchmarking the Full-Length BRB-seq protocol against competitor N shows similar performance for isoform detection. More than 50,000 isoforms can be detected at a sequencing depth of 12M reads per sample.
To have access to the deep-sequenced dataset contact us.
| Cell line/Tissue | Organism |
| HT1080 SMARCA4 KO | Human |
| hTEC | Human |
| iPSC microglia | Human |
| MCF7 | Human |
| HepG2_IGF1RKO | Human |
| Beas-2B | Human |
| dTHP-1 | Human |
| iPSC derived cardiomyocytes | Human |
| Endothelial | Human |
| Hepatocyte | Human |
| HEPG2 | Human |
| Hepatocyte | Human |
| SF9 | Spodoptera |
| A549 | Human |
| Breast Cancer (MCF7) | Human |
| B lymphoblast MM.1s. | Human |
| Hek293 | Human |
| HeLa Cells | Human |
| Cell line/Tissue | Organism |
| U2-OS | Human |
| Hek293 | Human |
| dTHP-1 | Human |
| AsPC-1 | Human |
| PBMC (TCD4) | Human |
| Skeletal muscle (LHCN-M2) | Human |
| HepaRG | Human |
| Macrophage (MV-4-11) | Human |
| PBMCs (Blood) | Human |
| Microglia | Human |
| Fibroblast Like Synoviocyte donor 1502 | Human |
| Fibroblast | Human |
| iPSC-derived neuron | Human |
| Human lung carcinoma epithelial cell line | Human |
| Human breast epithelial adenocarcinoma cell line | Human |
| Human liver hepatocellular carcinoma cell line | Human |
| Human cardiomyocytes derived from induced pluripotent stem cells (iPSCs) | Human |
Each Full-Length DRUG-seq kit contains reagents (including four pairs of Unique Dual Indexing adapters) sufficient for the complete library preparation process for four different DRUG-seq pools.
For instance, the 96-samples kit can be used to prepare up-to 96 samples distributed across up-to four different libraries.
The recommended range of RNA amount for each sample is 5’000 – 15’000 mammalian cells per well.
The minimum recommended RIN number is 7 and the A260/230 ratio (Nanodrop) should be in the 1.5-2.2 range.
The only difference between Full-Length DRUG-seq and standard RNA-seq data analysis is the demultiplexing step, which is used to assign sequencing reads to their sample of origin based on the BRB barcode sequence.
For a thorough description of Full-Length DRUG-seq data processing, please look at the user guide.
The barcode set for your kit is conveniently located on the kit label. Please refer to the label for accurate identification.
For optimal compatibility, ensure that you use the appropriate plate format (e.g., for kits designed for 96 reactions, the 96 well-plate format should be used). This ensures accurate and efficient processing of your samples. If you have any further questions or concerns, please contact our support team for assistance by email or using our live chat tool.
Full-Length BRB-seq provides comprehensive coverage of the full-length mRNA transcripts.
We, therefore, normally recommend sequencing 12-20 million reads for each sample, which enables the reliable and unbiased detection of over 20,000 genes.
Product
Number of Samples
Cell lysis module
Cell lysis module
UDI Expansion module
UDI X-Leap Expansion module
UDI X-Leap Expansion module
Each kit includes 4 UDI pairs. Add the expansion module if you need more unique indexes (total 16 UDI pairs available).
Determining the most suitable transcriptomic technology to drive your large-scale compound screen, clinical study, or to assess a panel of genetic perturbations can be a…
High-throughput’ in sequencing refers to the amount of DNA molecules read at the same time. Technologies are now capable of sequencing many fragments of DNA…
With a growing number of published 3’ mRNA-seq methods now available, researchers have more choices than ever for high-throughput and cost-effective transcriptomic screening. While broadly…