MERCURIUS™ Total Plant BRB-seq is a plant total RNA-seq kit for purified plant RNA samples, designed to support scalable whole-transcriptome profiling across plant research, crop science, and agrochemical R&D.
Built on Alithea Genomics’ BRB-seq technology, the workflow combines plant-focused rRNA depletion, early sample barcoding, and multiplexing of up to 96 samples in a single tube. The kit captures full-length coding and non-coding transcript information, supporting applications such as crop stress response, pathogen surveillance, plant protection product testing, herbicide toxicity studies, biomarker discovery, and plant genome annotation.
MERCURIUS™ Total Plant BRB-seq is designed for plant transcriptomics studies where researchers need scalable, cost-effective total RNA-seq with full-length transcript coverage.
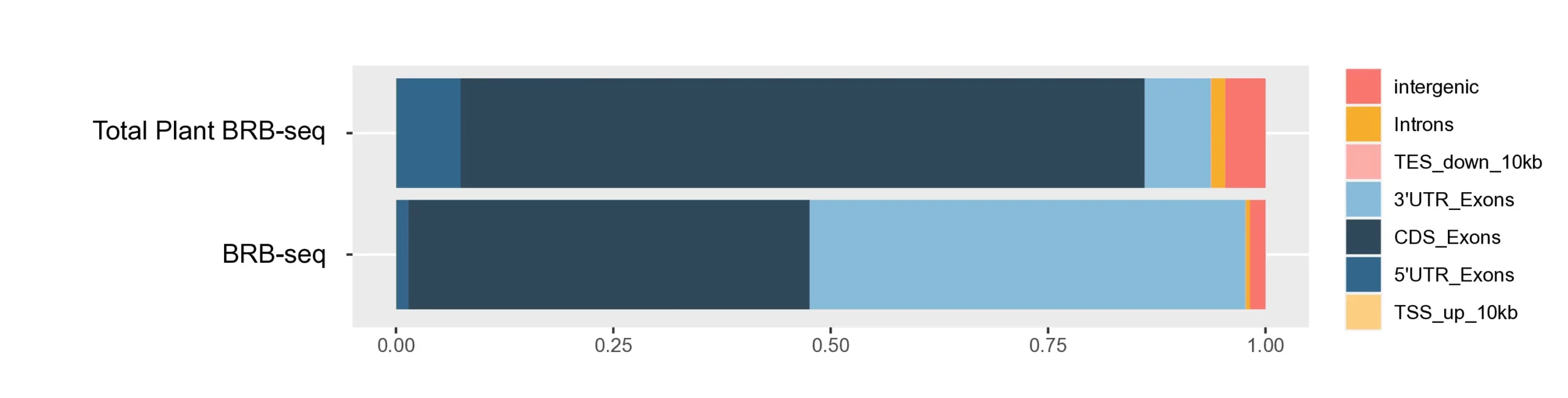
Stacked bar plots showing the distribution of mapped reads for Total Plant BRB-seq and BRB-seq in A. thaliana. A higher proportion of Total Plant BRB-seq reads map to coding (CDS) as expected for full-length methods.
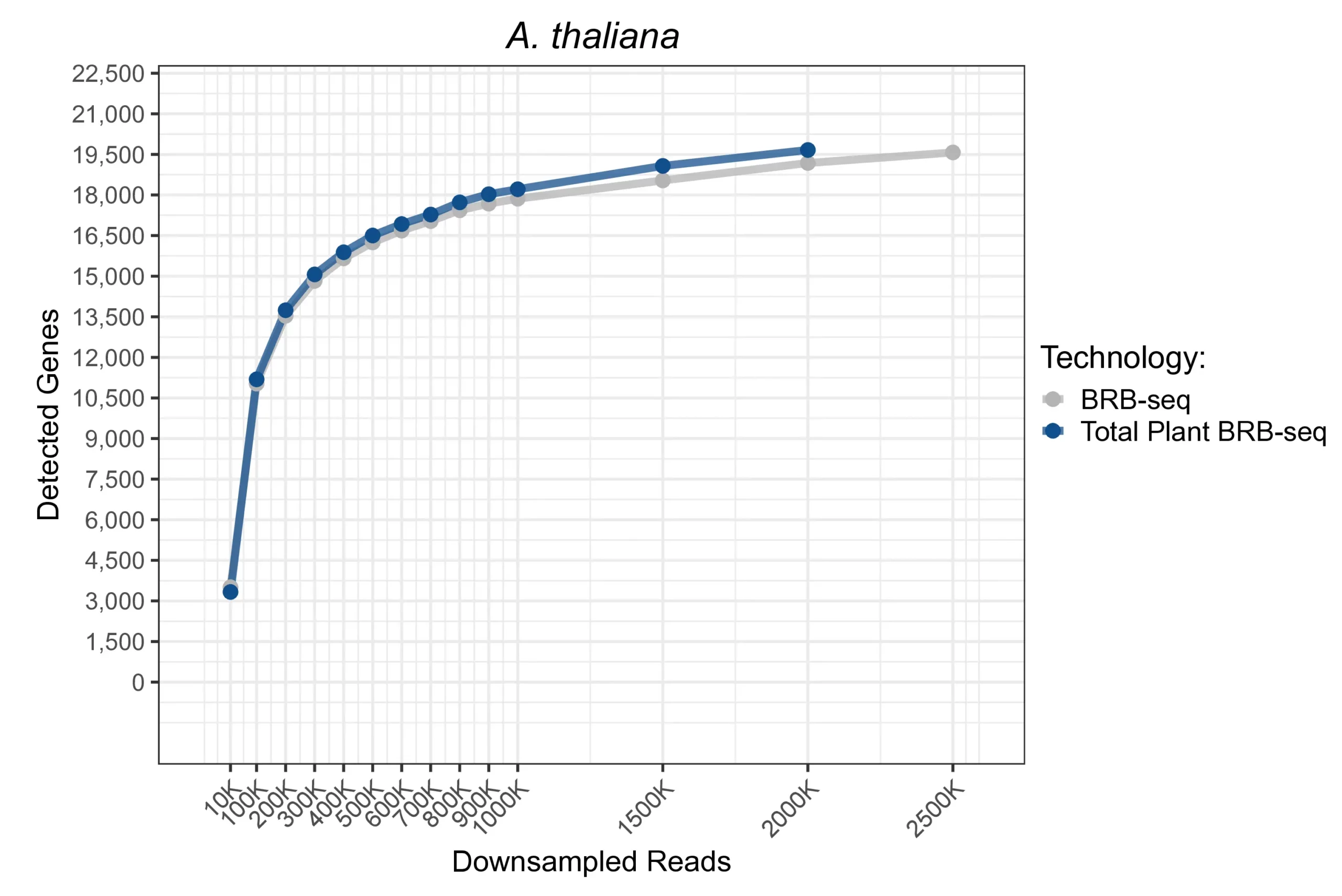
Saturation curves comparing Total Plant BRB-seq and BRB-seq gene detection across a range of downsampled read depths in A. thaliana. Total Plant BRB-seq detects a similar number of genes to BRB-seq across all downsampled sequencing depths, with both methods detecting around 18,000 genes at 1M reads per sample. The full-length information is especially beneficial for less well-annotated genomes, where 3’ UTR may not be complete.
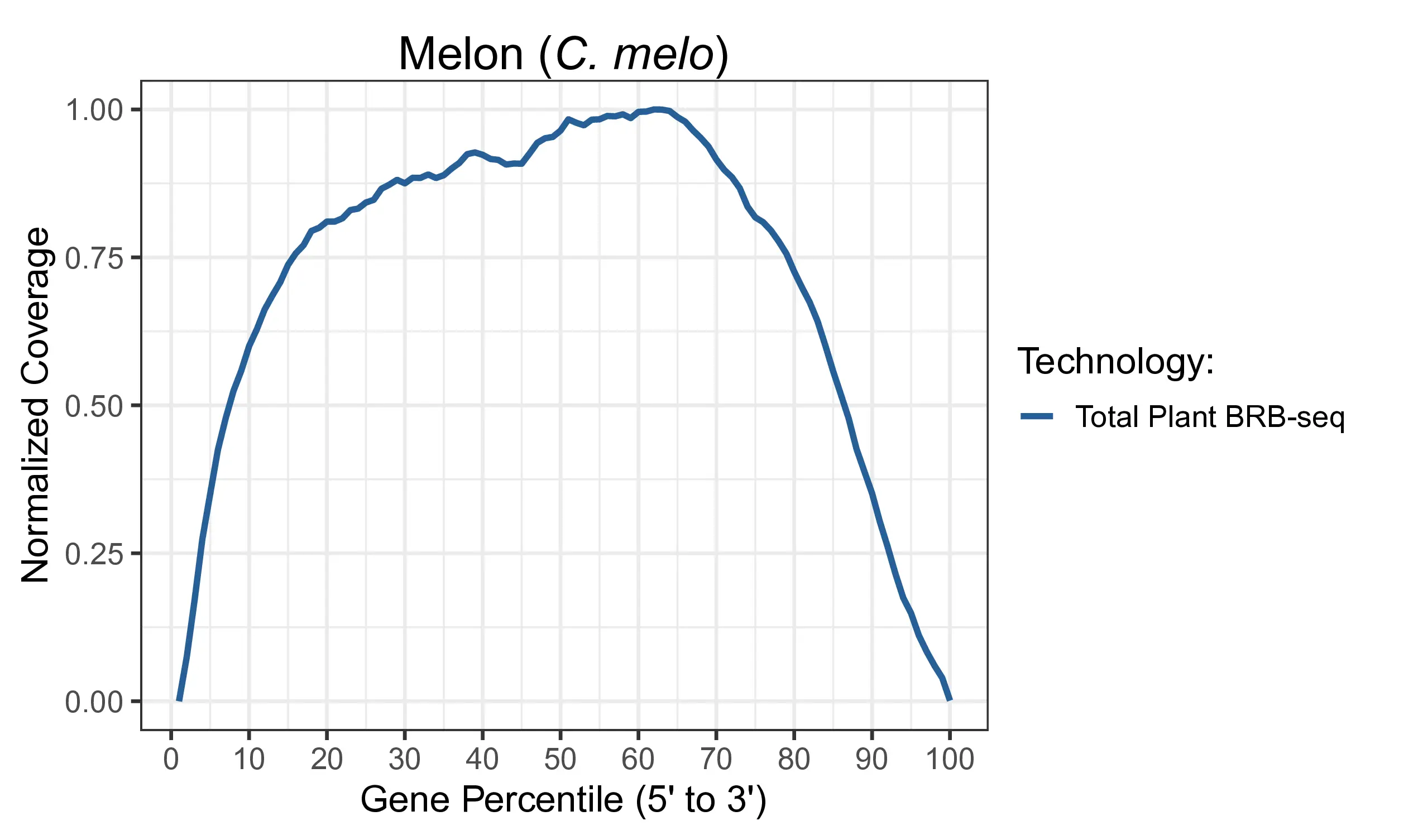
Normalized 5’ to 3’ read coverage across the transcript body for Total Plant BRB-seq in C. melo. Reads are distributed broadly across the full transcript length, confirming that Total Plant BRB-seq captures full-length transcript information rather than the 3′-bias associated with standard poly-A enrichment methods like BRB-seq.
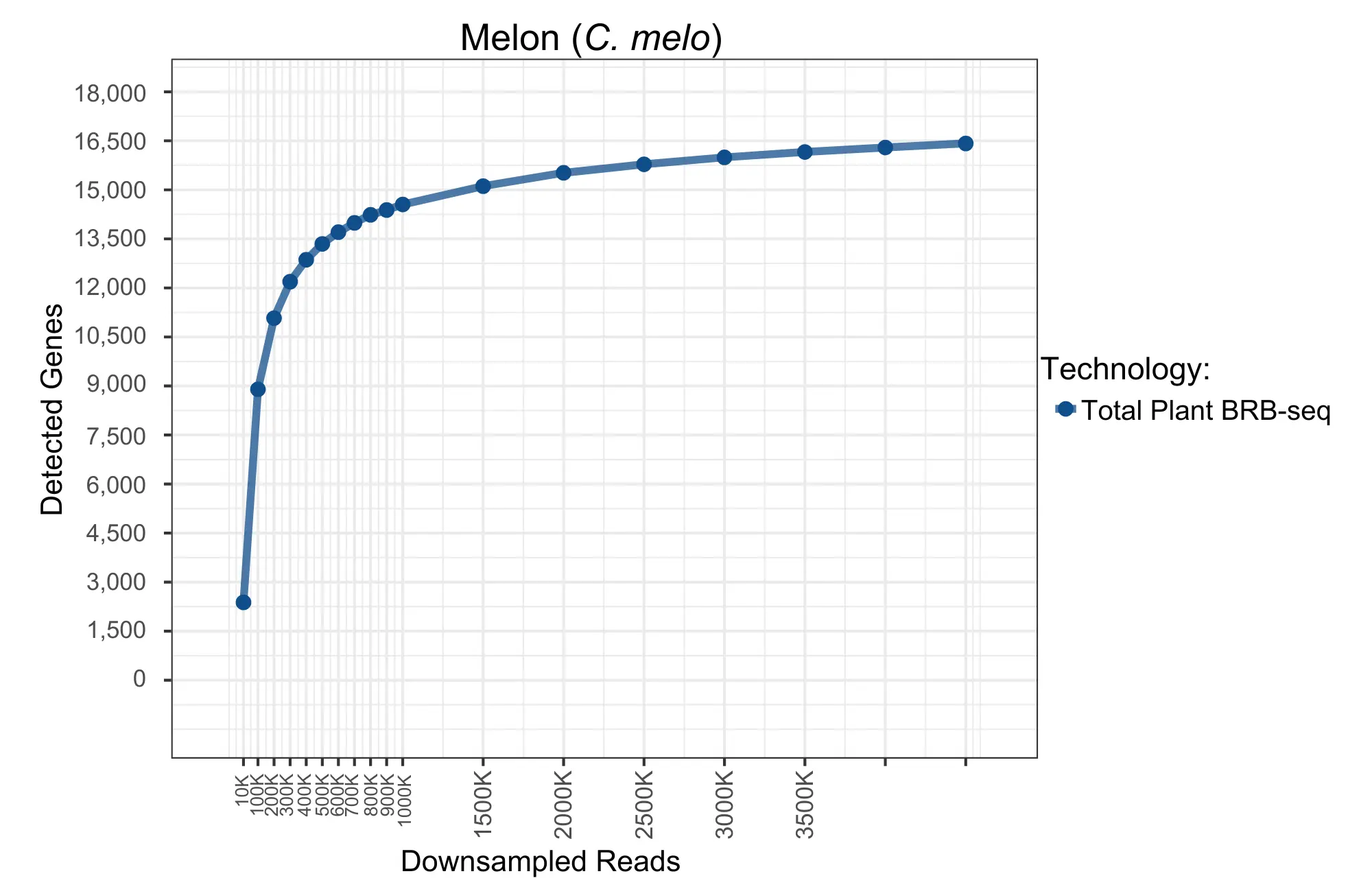
Gene detection saturation curve for Total Plant BRB-seq in C. melo, with detected genes as a function of downsampled read depth. Gene detection increases rapidly below 500K reads per sample, demonstrating broad coverage of the C. melo transcriptome.
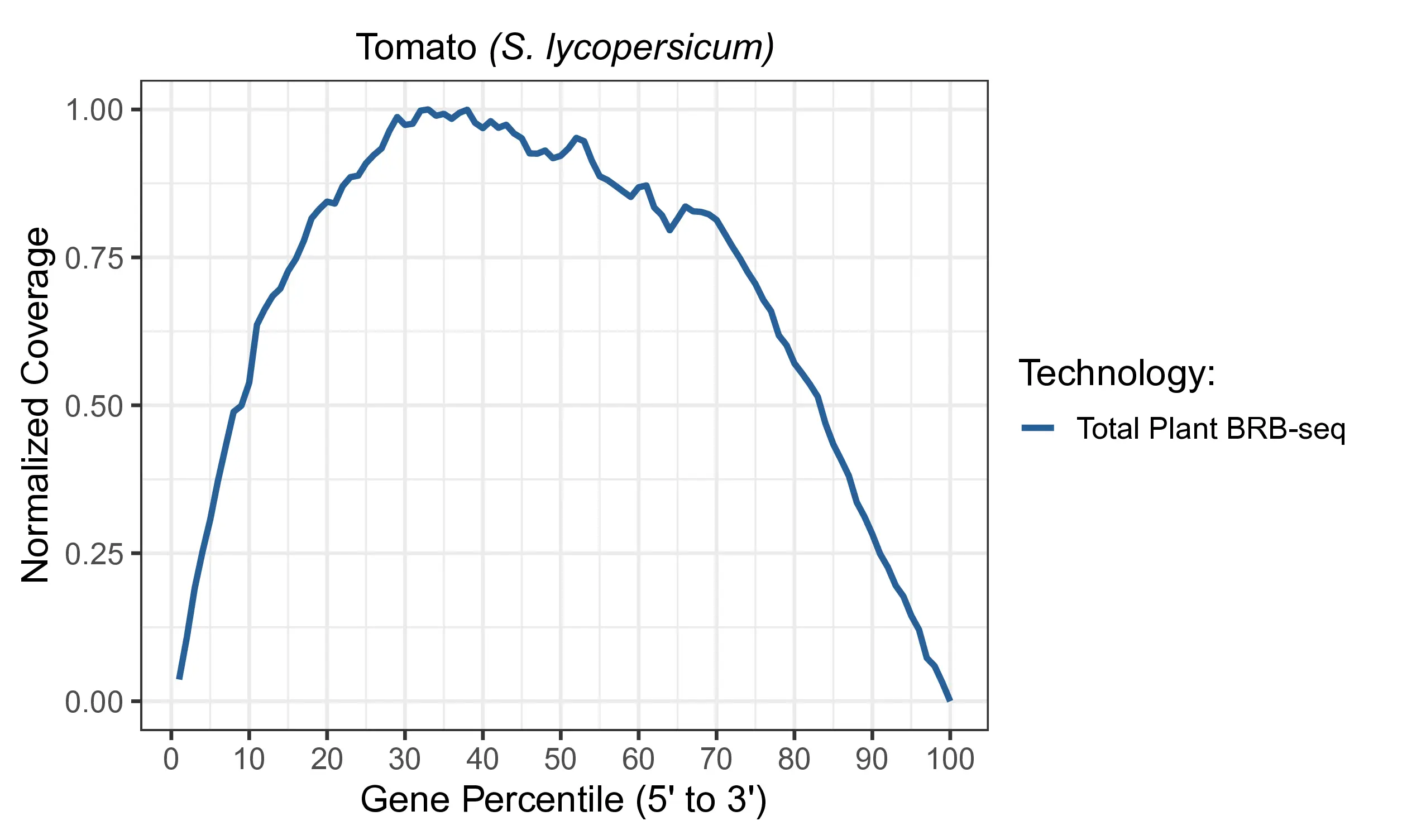
Normalized 5’ to 3’ read coverage across the transcript body for Total Plant BRB-seq in S. lycopersicum. Reads are distributed broadly across the full transcript length, confirming that Total Plant BRB-seq captures full-length transcript information rather than the 3′-bias associated with standard poly-A enrichment methods like BRB-seq.
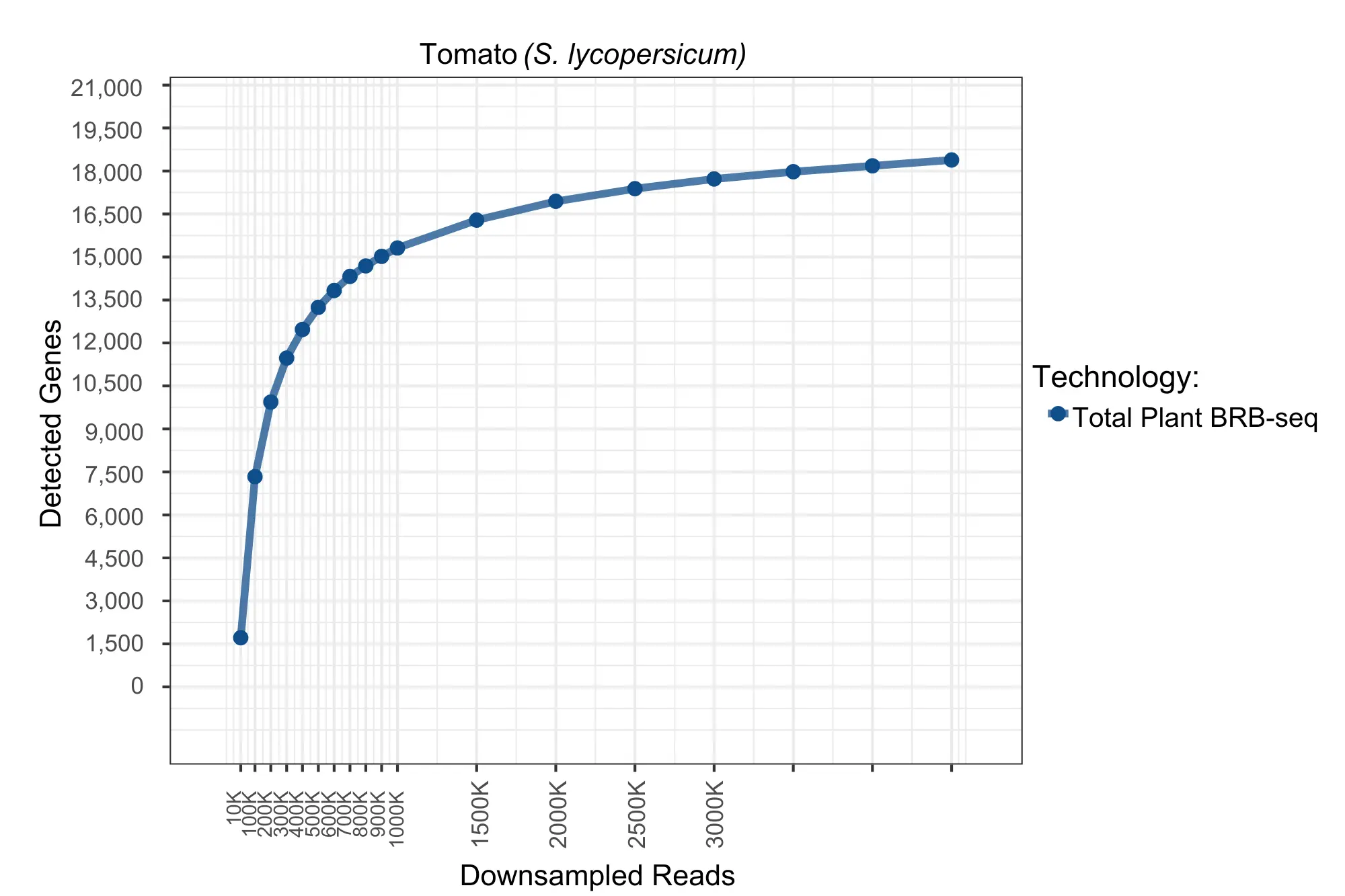
Gene detection saturation curve for Total Plant BRB-seq in S. lycopersicum, with detected genes shown as a function of downsampled read depth. Gene detection increases rapidly below 500K reads per sample and plateaus near saturation of approximately 16,500 genes at 4.5M reads.
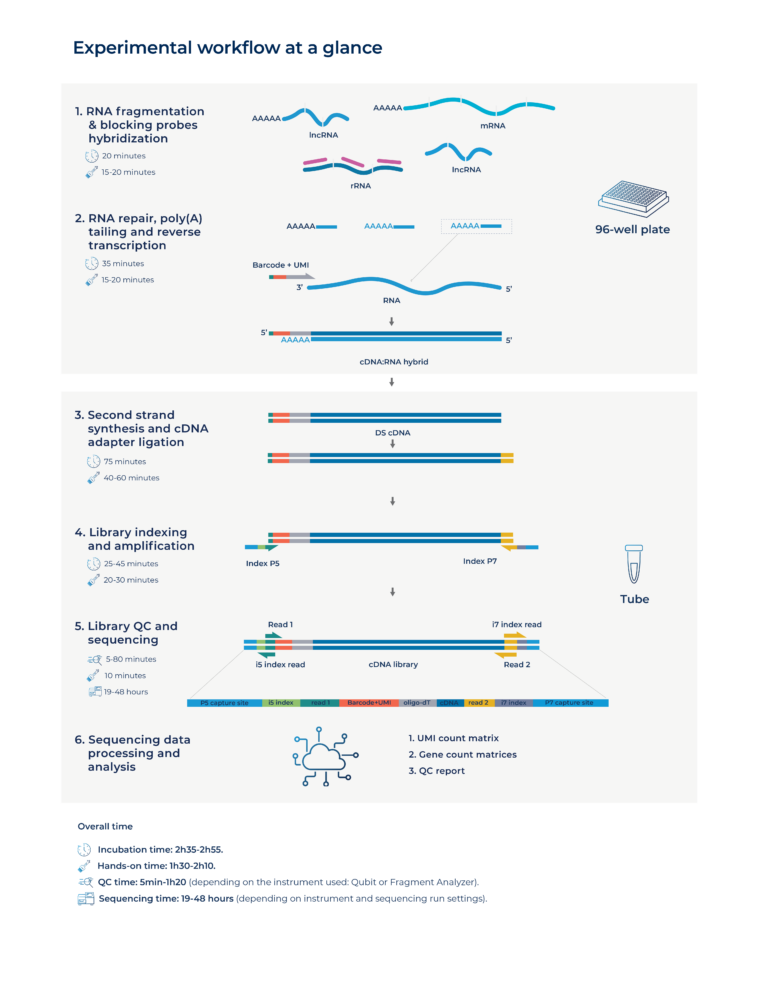
Each kit includes 4 Unique Dual Index (UDI) pairs, so you can prepare up to 4 indexed libraries (pools) per kit.
The tested input range is 100 pg to 100 ng total RNA per well. For best results (library complexity + uniformity), aim for 10–100 ng per well, and pool at least 8 wells per library.
Because Total BRB-seq uses early multiplexing, it’s important that RNA quantity and quality are consistent across samples (e.g., RIN > 7, 260/230 > 1.5, and ~±10% input uniformity).
Total BRB-seq is designed for total RNA sequencing (not just mRNA), including coding and non-coding transcripts, and includes an rRNA depletion step prior to library prep.
We recommend 3-5 million reads for gene detection and >10 million reads for isoform and transcript analysis.
Yes, there is one extra step: after standard index demultiplexing, you demultiplex by sample barcodes to generate per-sample gene/transcript count outputs. The workflow supports producing outputs like UMI count matrices, gene count matrices, and a QC report.
Go to the “Resources” section of this page and click on the button to download the barcode files for the product you are using.
Yes. If you are not ready to run kits internally, Alithea can run the workflow and deliver FASTQ files, gene count matrices, and analysis report files.
* Contact us to inquire about compatibility with other species.
Product
Catalog Number
MERCURIUS™ UDI X-Leap Expansion module
MERCURIUS™ Full-Length Post-Pooling Preparation Module (4 libraries)
Each kit includes 4 UDI pairs. Add the expansion module if you need more unique indexes (total 16 UDI pairs available).
Determining the most suitable transcriptomic technology to drive your large-scale compound screen, clinical study, or to assess a panel of genetic perturbations can be a…
High-throughput’ in sequencing refers to the amount of DNA molecules read at the same time. Technologies are now capable of sequencing many fragments of DNA…
With a growing number of published 3’ mRNA-seq methods now available, researchers have more choices than ever for high-throughput and cost-effective transcriptomic screening. While broadly…