Watch Launch Webinar
Recording available
MERCURIUS™ 1536 DRUG-seq is an automatable, ultra-high-throughput bulk 3’ mRNA-seq technology designed for frozen 2D cell lines and primary cells in 1536-well assay plates. It enables screening teams to build standardized, foundational compound-response AI training datasets of thousands to millions of transcriptomic profiles, at the scale where 384-well throughput is insufficient.
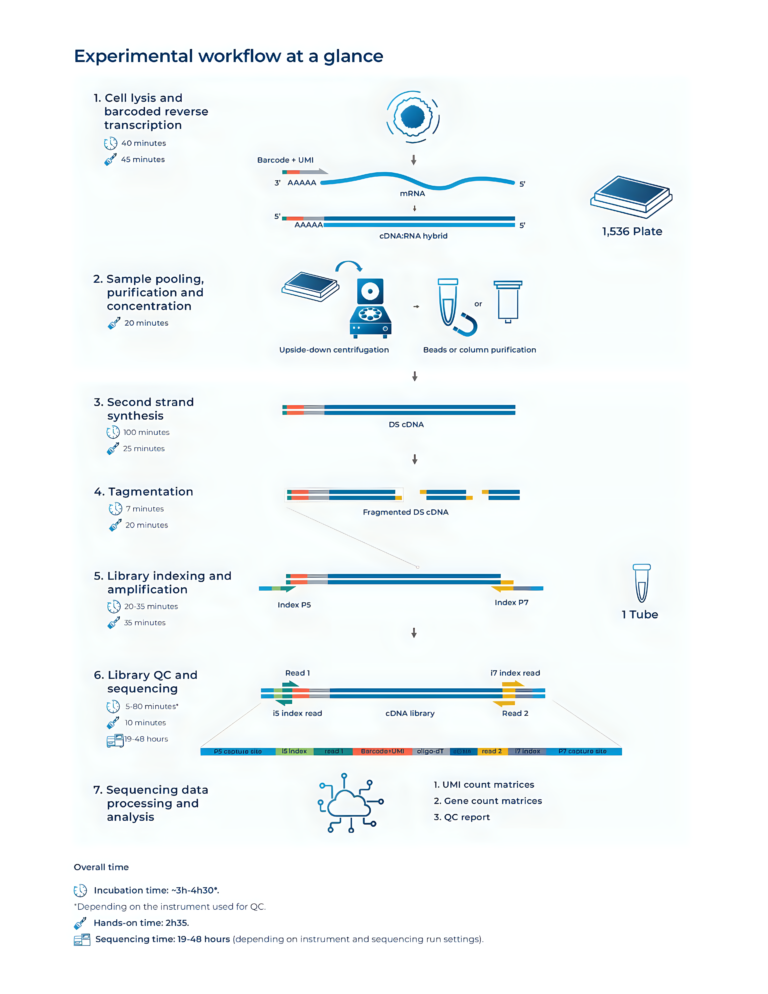
Cell lysis and barcoded reverse transcription are performed directly in the 1536-well culture plate, followed by pooling of the 1536 samples into a single tube, resulting in a library preparation hands-on time of approximately 2.5 hours without compromising depth, data quality, or sensitivity compared with sample-by-sample methods.
The technology allows teams to robustly link compounds to biological responses and makes ultra-high-throughput transcriptomics a reality for large-scale compound profiling, safety assessment, dose–response, and structured, foundational perturbation datasets for AI-driven drug discovery.
AI-ready ultra-high-throughput whole-transcriptome profiling with MERCURIUS™ 1536 DRUG-seq
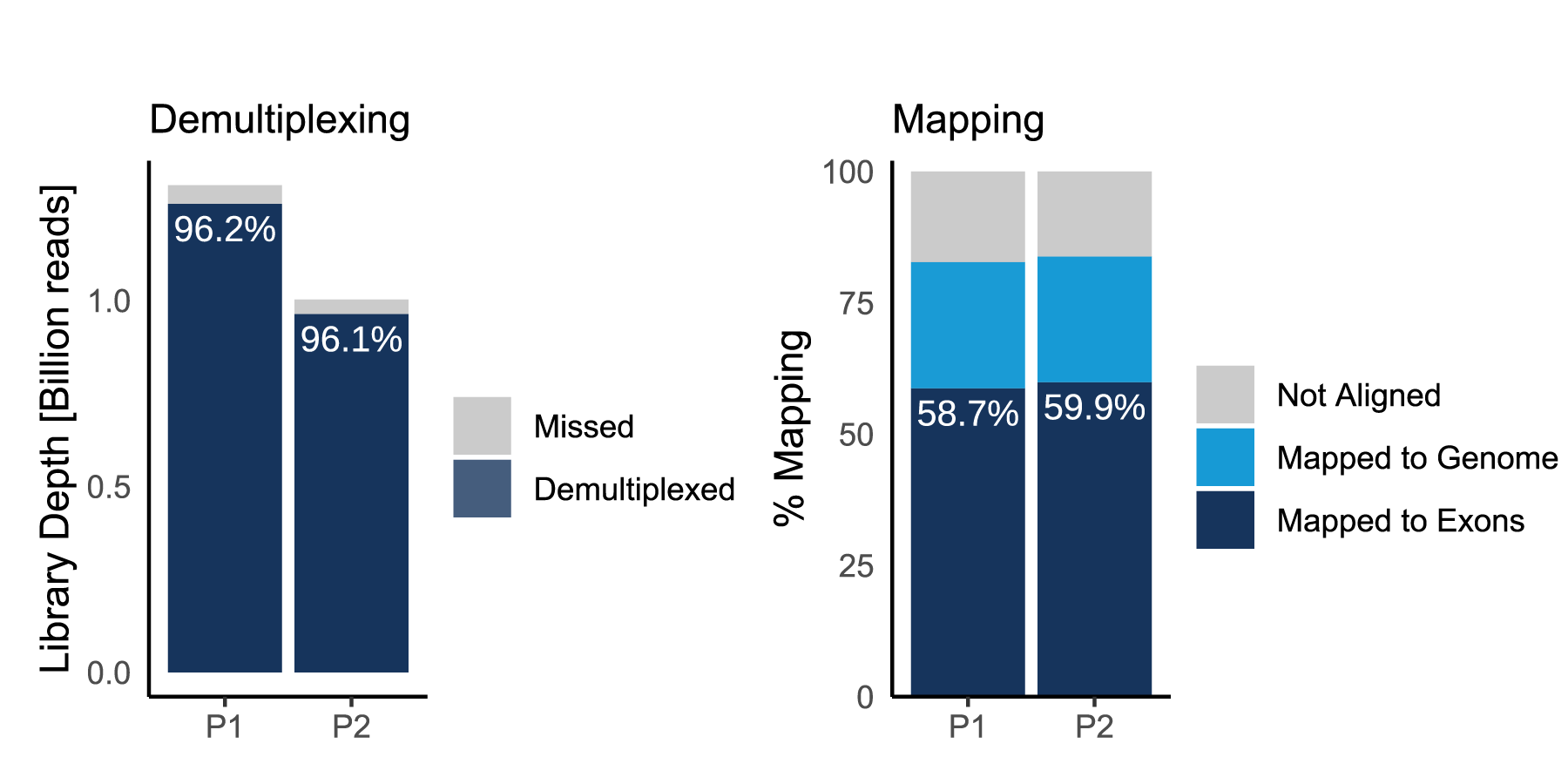
Sequencing quality metrics for two independently prepared MERCURIUS™ DRUG-seq libraries, each containing 1,536 multiplexed samples.
Left: demultiplexing performance showing >96% assignment of reads to individual samples.
Right: mapping statistics indicating 58–60% of reads mapped to exonic regions. Libraries were sequenced at an average depth of approximately 0.7 million reads per sample.
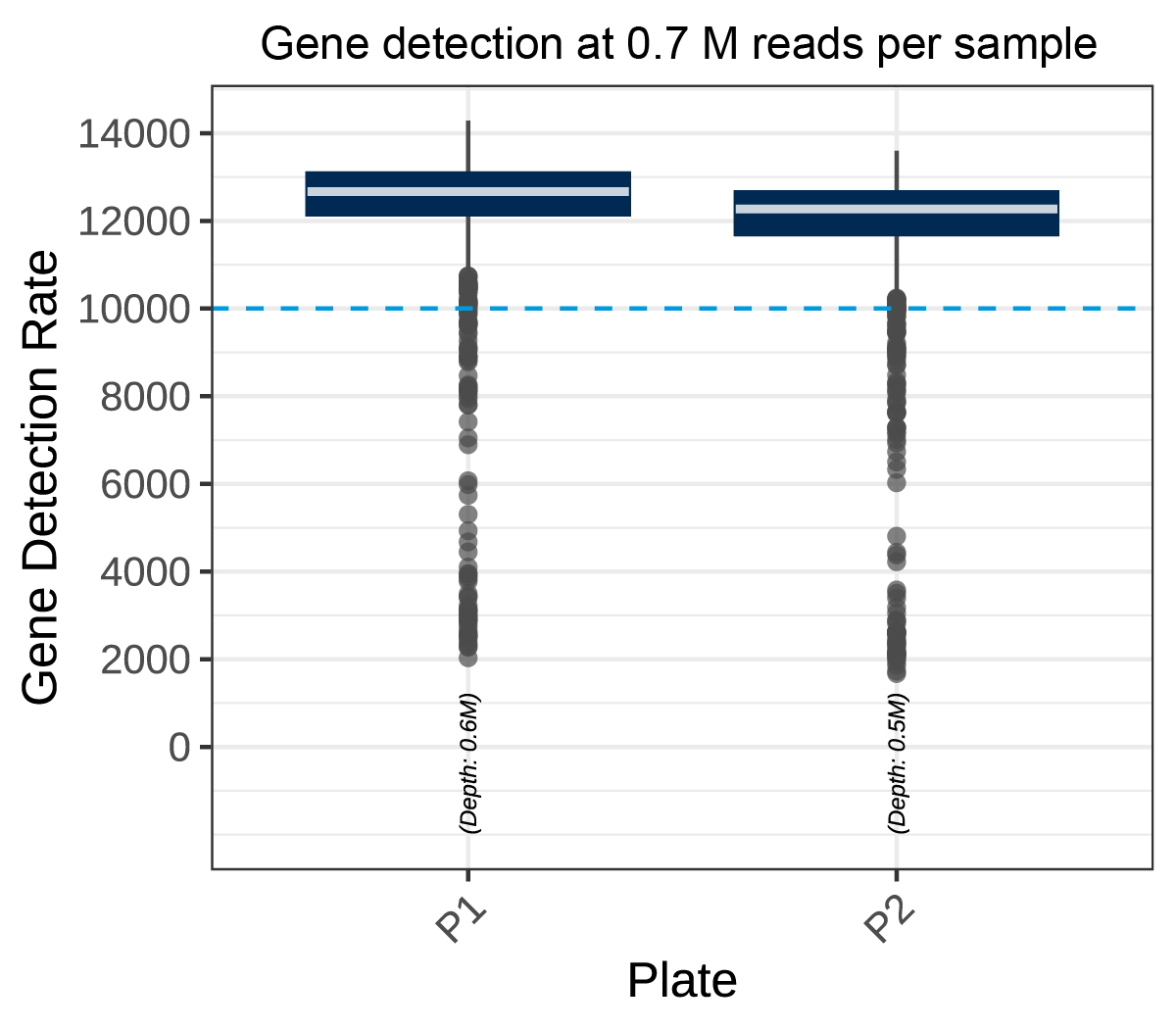
Gene detection rate across 1536 samples in the two independent MERCURIUS™ 1536 DRUG-seq libraries. Median gene detection exceeded 12,000 genes in both libraries, with highly comparable distributions between plates, demonstrating uniform library preparation and sequencing performance across more than 3,000 samples.
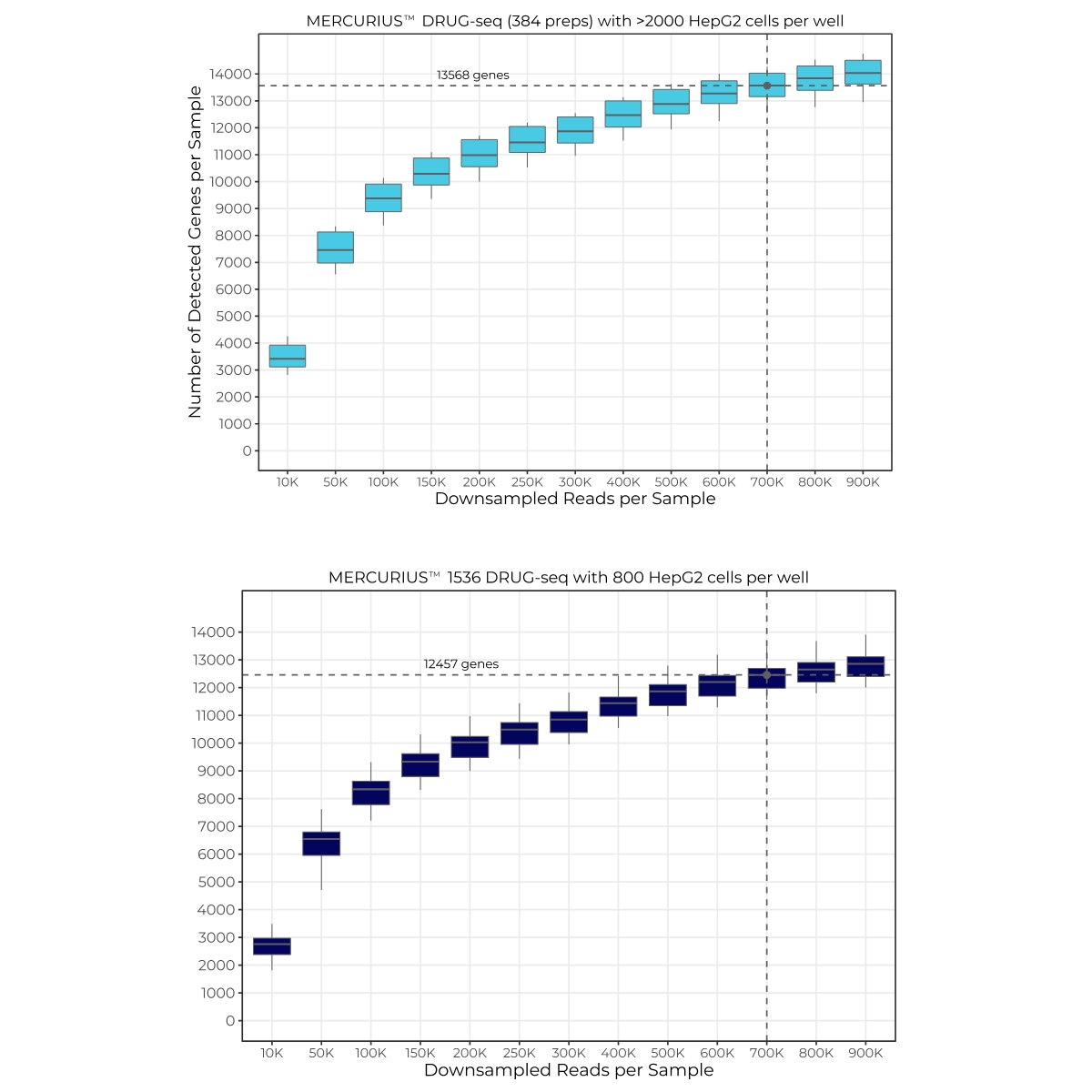
Number of detected genes per sample across downsampled sequencing depths for MERCURIUS™ DRUG-seq in 384-well format with >2,000 HepG2 cells per well and for MERCURIUS™ 1536 DRUG-seq with 800 HepG2 cells per well. At 700K reads per sample, a median of 13,568 and 12,457 genes were detected, respectively, demonstrating robust transcriptome coverage with MERCURIUS™ 1536 DRUG-seq, even for very low cell numbers. Only DMSO negative control samples from full, compound-treated 384-well (n=24) and 1536-well (n=60) plates are shown.
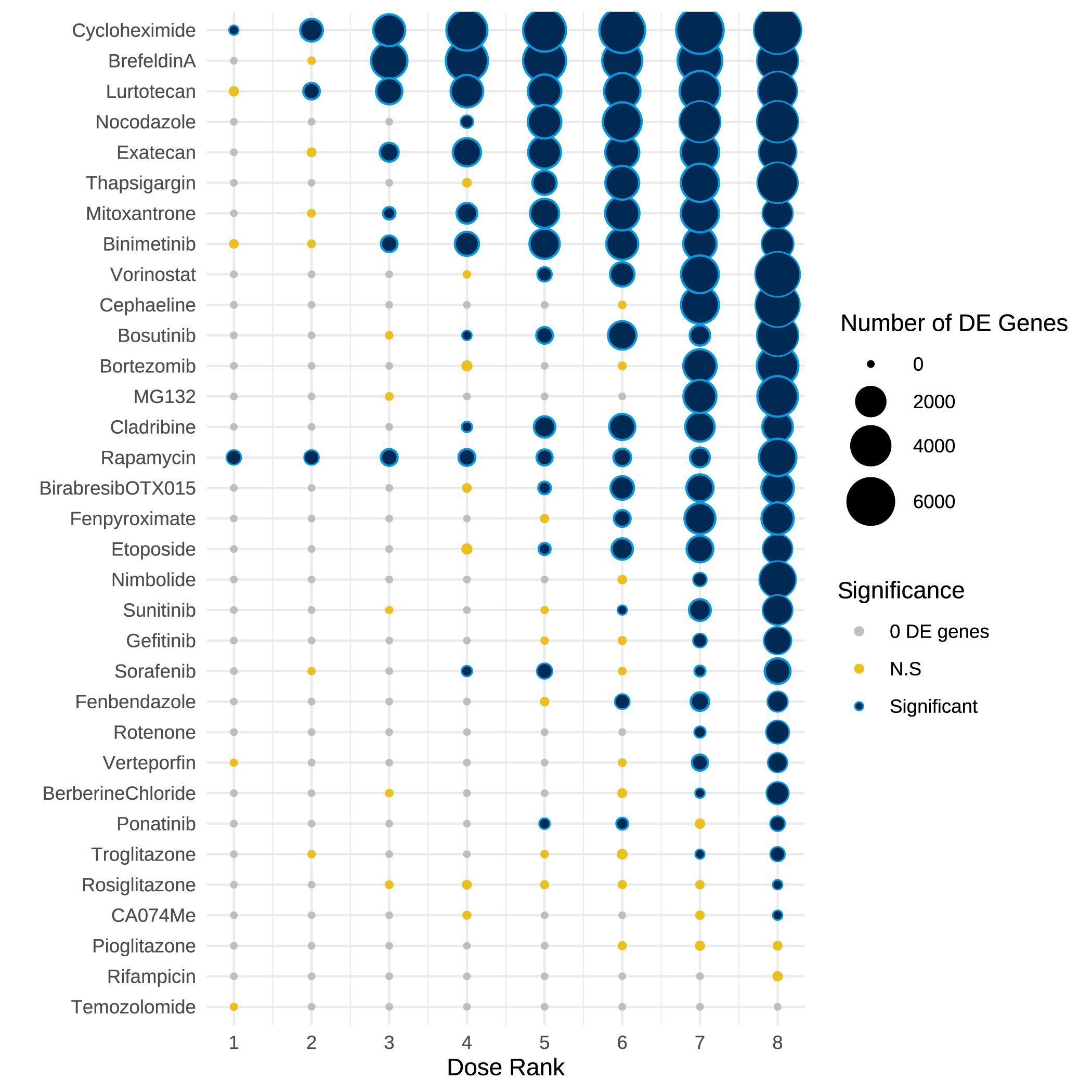
Bubble size indicates the number of significantly differentially expressed genes detected at increasing compound concentrations, with color denoting significance. MERCURIUS™ DRUG-seq successfully captures diverse transcriptional perturbations and enables ranking of compounds based on the magnitude of their gene expression responses.
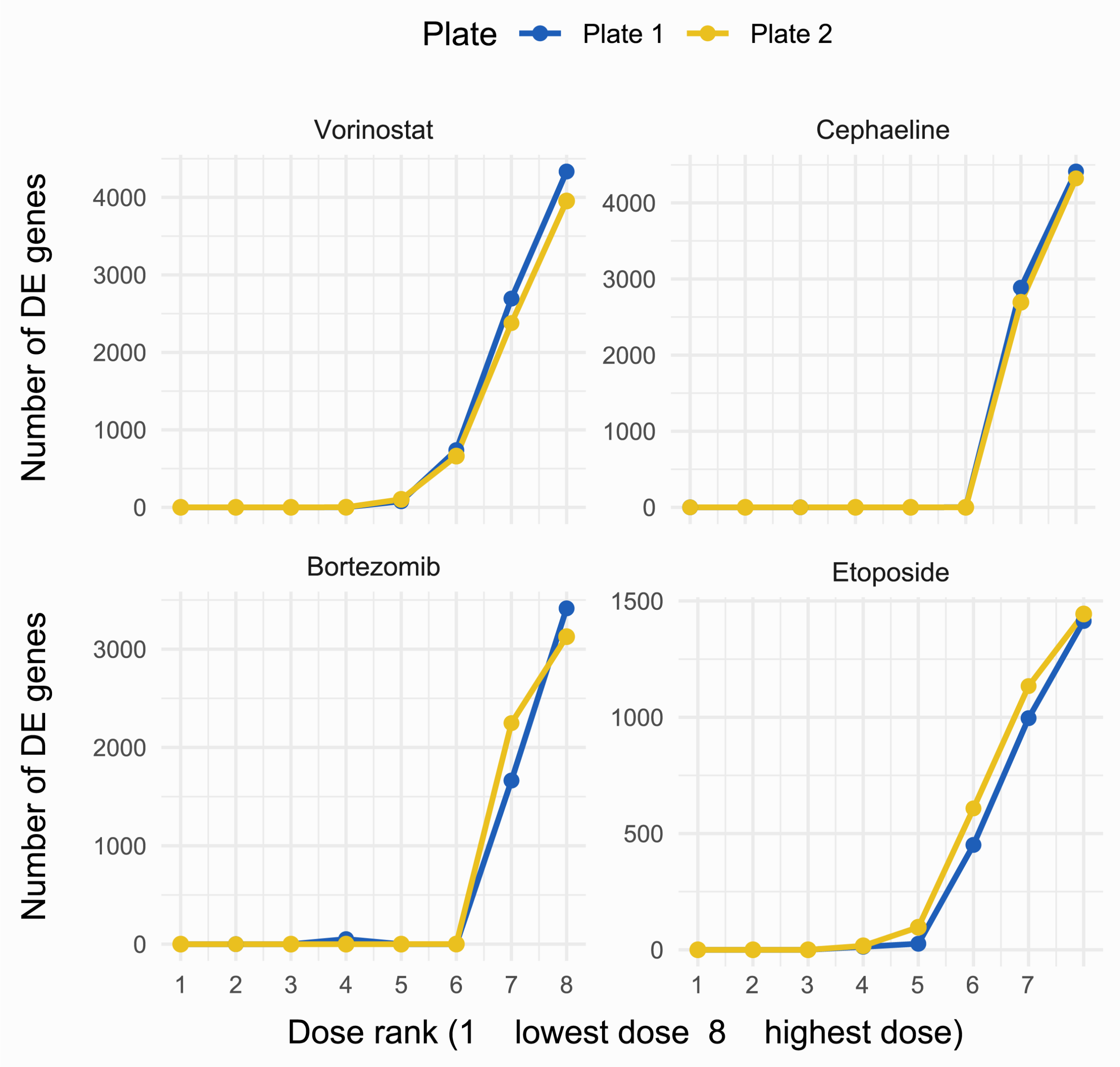
Line plots comparing DE responses for the four most transcriptionally active compounds across two independently processed plates. Concordant dose-response curves across both plates demonstrate the inter-plate reproducibility of MERCURIUS™ 1536 DRUG-seq, confirming that compound-induced transcriptional signatures are consistently captured at screening scale.
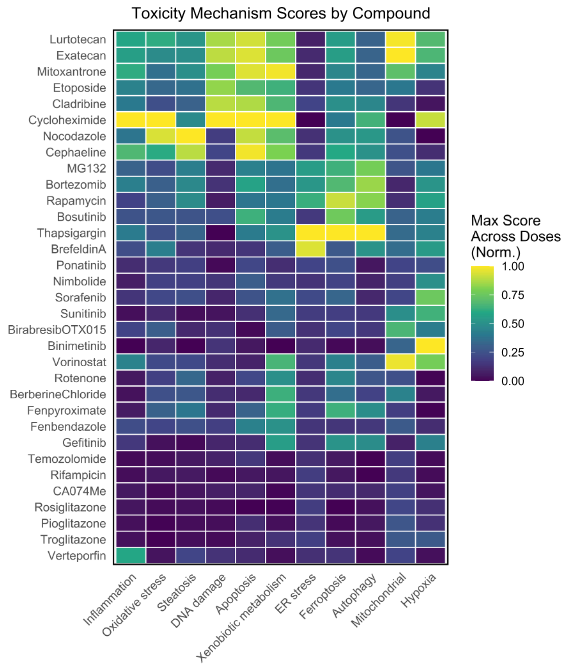
Heatmap showing normalized activity scores for 12 toxicity-related cellular pathways derived from transcriptomic profiles generated using MERCURIUS™ 1536 DRUG-seq. Analysis of 33 compounds reveals mechanism-specific responses consistent with known pharmacology. For example,topoisomerase inhibitors (Etoposide, Mitoxantrone, Lurtotecan, and Exatecan) exhibit strong DNA damage signatures, while Thapsigargin and Brefeldin A induce pronounced endoplasmic reticulum stress responses.

| HepaRG | Liver |
| HepG2 | Liver (HCC) |
| Huh7 | Liver (HCC) |
| Hep3B | Liver (HCC) |
| PHH (Primary Human Hepatocytes) | Primary liver |
| NCI-H295R | Adrenal/liver metabolism |
| MCF7 | Breast cancer |
| A549 | Lung carcinoma |
| H358 | Lung cancer |
| NCI-H1563 / H1048 | Lung cancer |
| DLD-1 | Colorectal cancer |
| SW837 | Colorectal cancer |
| HCT116 | Colorectal cancer |
| LS180 | Colorectal cancer |
| COLO201 | Colorectal cancer |
| C2BBe / C2BBe1 | Colorectal |
| GP5d | Colorectal |
| U2OS | Osteosarcoma |
| A172 | Glioblastoma |
| PSN-1 | Pancreatic cancer |
| AsPC-1 | Pancreatic cancer |
| SU.86.86 | Pancreatic cancer |
| A375 | Melanoma |
| HaCaT | Keratinocyte |
| UMUC3 | Bladder cancer |
| 5637 | Bladder cancer |
| HT1197 | Bladder cancer |
| Cal29 | Bladder cancer |
| UBLC1 | Bladder cancer |
| PBMC | Primary blood |
| Jurkat | T-cell leukemia |
| Raji | B-cell lymphoma |
| THP-1 | Monocyte |
| U937 | Monocyte |
| MV-4-11 | AML |
| MOLM13 | AML |
| HL60 | Leukemia |
| MM1S | Myeloma |
| KMS12BM | Myeloma |
| CD4+ / CD8+ T cells | Primary immune |
| Tregs / TILs | Immune subsets |
| CD3 T cells | Immune |
| iPSC | Pluripotent |
| iPSC-derived neurons | Neural |
| iPSC-derived cardiomyocytes | Cardiac |
| iPSC-derived cortical neurons | Neural |
| iPSC-derived organoids | Various |
| HMC3 | Microglia |
| Luhmes | Dopaminergic neuron |
| IMR90 | Fibroblast (used in brain spheres) |
| iCell GlutaNeurons | Neurons |
| Astrocytes (human/mouse/rat) | Glial |
| NHDF | Dermal fibroblast |
| MEF | Mouse embryonic fibroblasts |
| HEK293 / HEK293T | Kidney (transformed) |
| ARPE-19 | Retinal epithelium |
| NHEK | Keratinocytes |
| Lung epithelial | Epithelial |
| RPTEC/TERT1 | Kidney (proximal tubule) |
| T84 | Colon epithelium |
| Human adipocytes | Primary |
| Brown adipocytes | Metabolic |
| Visceral adipocytes | Primary |
| Mouse/canine adipose | Animal |
MERCURIUS™ 1536 DRUG-seq is a high-throughput whole transcriptome profiling workflow designed for 1536-well assay plates. It enables discovery teams to generate large, standardized compound-response datasets directly from screening-scale experiments.
The 1536 DRUG-seq technology enables the generation of high-quality sequencing data from 400 to 1,000 mammalian cells per well.
The only difference between DRUG-seq and standard RNA-seq data analysis is the demultiplexing step, which is used to assign sequencing reads to their sample of origin based on the DRUG-seq barcode sequence.
For a thorough description of DRUG-seq data processing, please refer to the DRUG-seq kit data analysis user guide.
The barcode set for your kit is conveniently located on the kit label. Please refer to the label for accurate identification.
For optimal compatibility, ensure that you use the appropriate plate format (e.g., for kits designed for 96 reactions, the 96 well-plate format should be used). This ensures accurate and efficient processing of your samples. If you have any further questions or concerns, please contact our support team for assistance by email or using our live chat tool.
No. The RT incubation is performed directly in the 1536-well plate using a standard incubator or oven at 37°C. This helps avoid one of the practical bottlenecks of working in 1536-well PCR formats.
The workflow is designed for automated high-throughput environments. We recommend using microplate dispensers and liquid handling robots for RT/lysis plate preparation, oil dispensing, and transfer of master mix into 1536-well plates.
* Contact us to inquire about compatibility with other species.
** Find the list of validated cell lines here.
Product
Number of Samples
MERCURIUS™ Cell Lysis Modules
MERCURIUS™ Cell Lysis Modules
MERCURIUS™ Standard Post-Pooling Preparation Module (4 libraries)
For the first time, 1536-well whole transcriptome profiling brings biologically rich readouts to primary screening and large-scale perturbation dataset generation. In this webinar, Alithea Genomics…
Biomarker discovery using gene expression signatures has transformed pharmaceutical discovery and development, from early hit triage and target validation to toxicology, dose optimization, and patient…
Next-generation AI models for drug discovery are only as powerful as the quality, size, and perturbation-richness of their training data. Yet no publicly available dataset…
As the SOT Annual Meeting and ToxExpo 2026 approaches, we take a pre-conference look at the program through a transcriptomics-focused lens. One overall shift is…

