MERCURIUS™
Full-Length Plant BRB-seq service
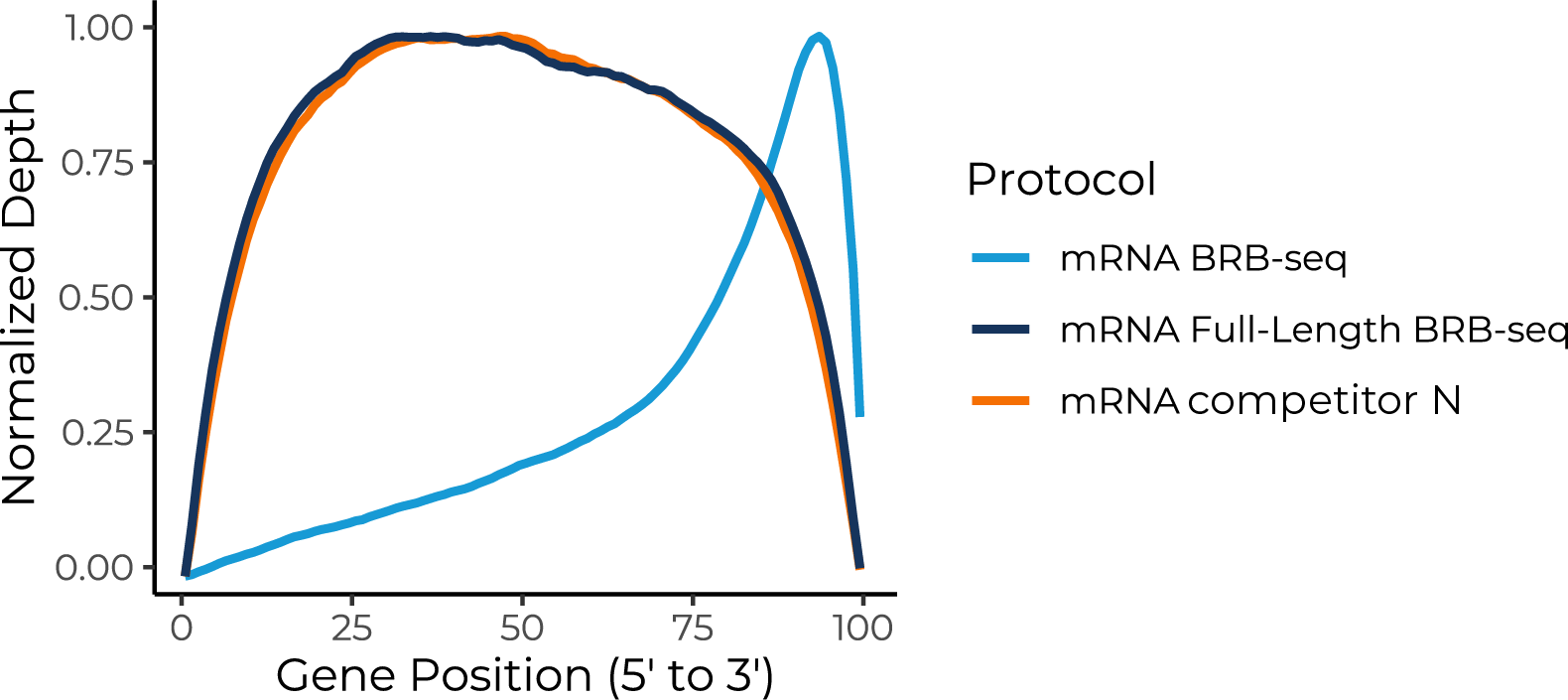
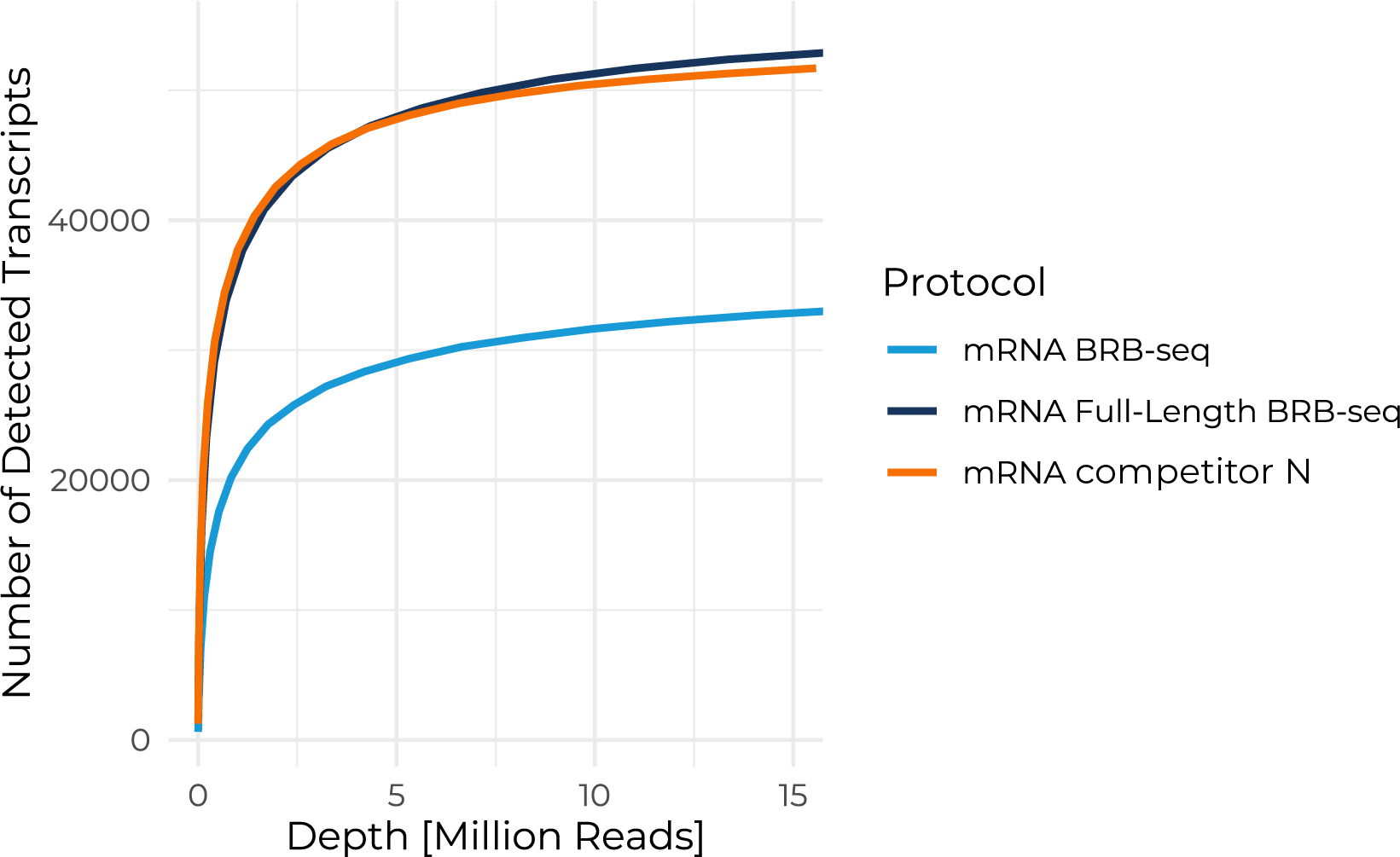
Full-length mRNA-seq combined with massive sample multiplexing.
MERCURIUS™
Full-length mRNA-seq combined with massive sample multiplexing.





The MERCURIUS™ Full-Length Plant BRB-seq service offers a convenient and streamlined solution for full-length mRNA transcriptomics projects of any size.
Clients can send us purified plant RNA samples, which are always quality-checked before launching our Full-Length Plant BRB-seq pipeline. During the process, we always keep clients informed at defined checkpoints so that we can decide together how to best proceed to the next steps.
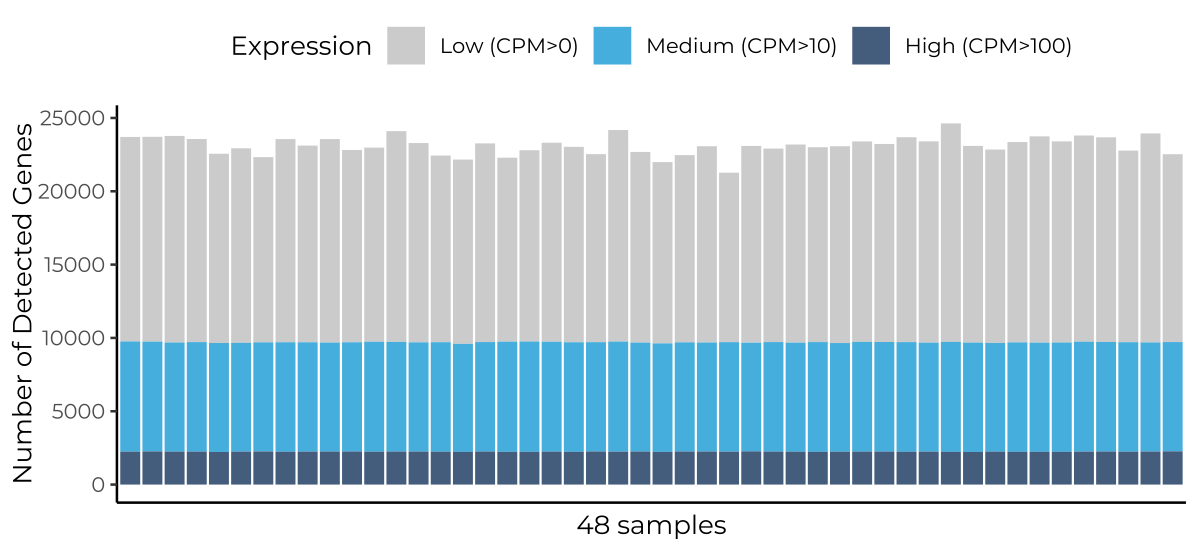
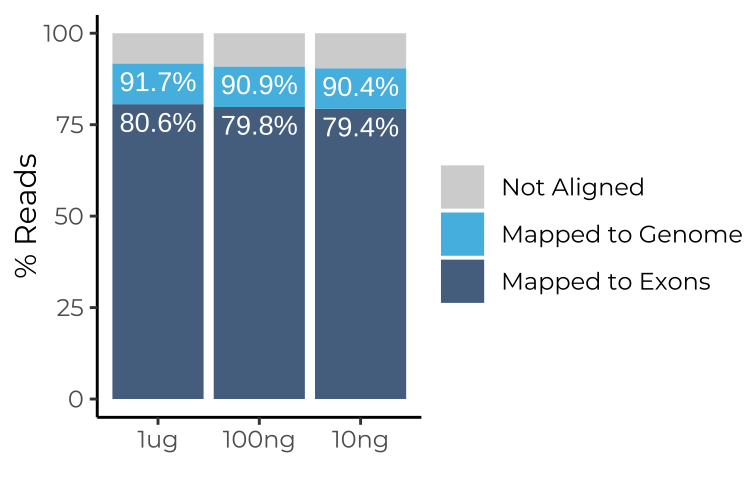
Next generation sequencing and data pre-processing (including alignment to the genome of choice) are part of our standard service as well. As a result, we provide our clients raw data, sequencing and alignment reports, and gene count matrices which can be used for downstream gene expression analysis.
Optional downstream differential gene expression analysis are also available upon request.

Step 1
Step 2
Step 3
Step 4
(Nanodrop and Fragment Analyzer)
![]() 1 week
1 week
Step 5
![]() 2 days
2 days
Step 6
(Qubit, Fragment analyzer, shallow sequencing)
![]() 1 week
1 week
Step 7

![]() 1 week
1 week
Step 8
Step 9



Receive email updates on our latest products and services, news and event updates and more. No ads, no spam.


