Cell lysis module
-
Optimized lysis buffer for complete lysis and efficient reverse transcription.
-
Compatible with DRUG-seq library prep kits.



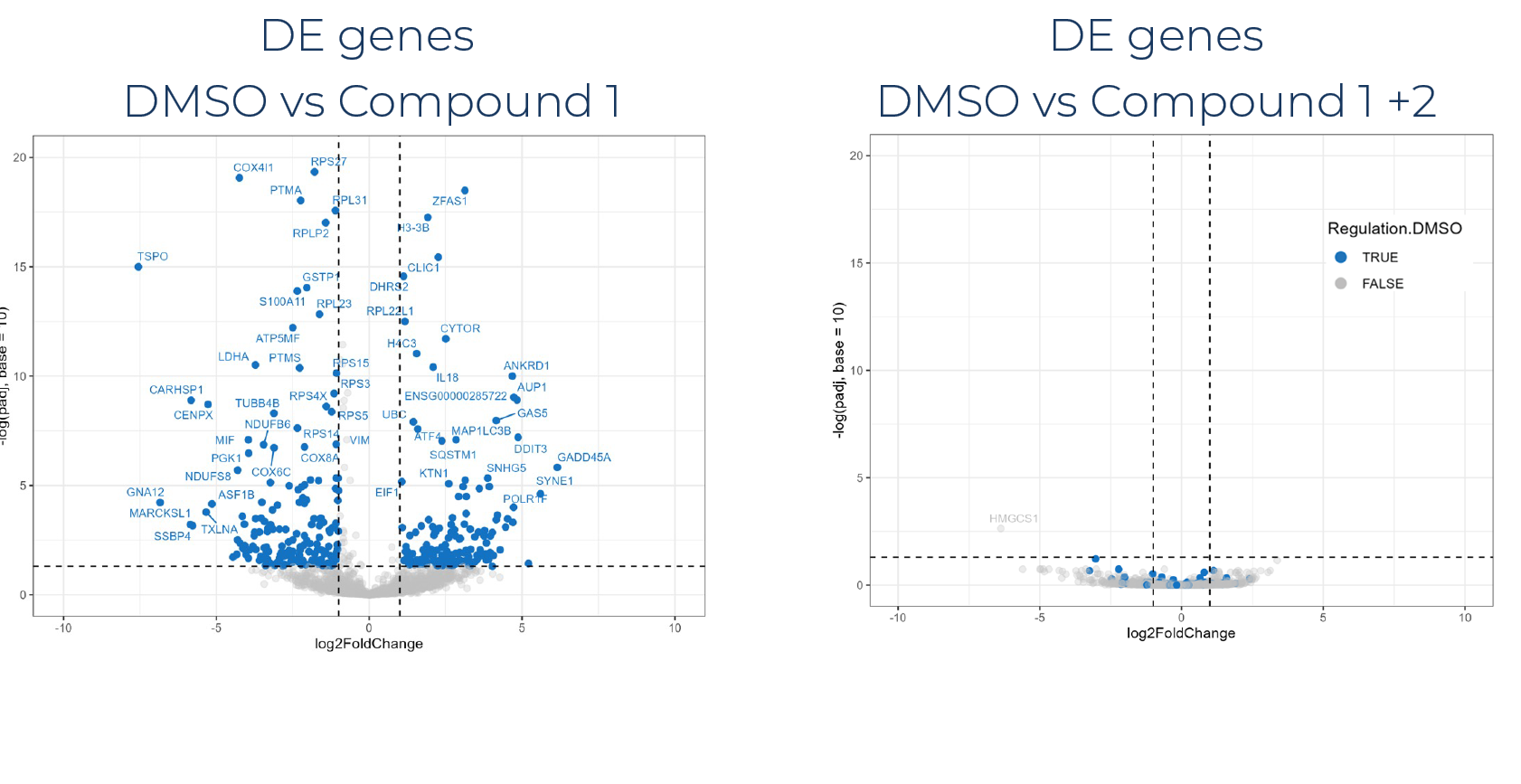
Massively multiplexed and extraction-free library preparation kits
Compatible with Illumina® and AVITI™ sequencers.
Catalog number | #10841 |
#11041 |
#10851 |
#11051 |
|
Total preps
|
96 | 384 | 384 | 1,536 |
|
Sample multiplexing and plate format
|
96 | 96 | 384 | 384 |
|
Barcoded oligo-dT plates included
|
1 | 4 | 1 | 4 |
|
UDI pairs included
|
4 | 4 | 4 | 4 |
| Documentation | ||||
| Cat ##10841 | ||||
|---|---|---|---|---|
|
Total reactions
|
96 | |||
|
RNA multiplexing format
|
96 | |||
|
UDI pairs included
|
4 | |||
| Cat ##11041 | ||||
|---|---|---|---|---|
|
Total reactions
|
384 | |||
|
RNA multiplexing format
|
96 | |||
|
UDI pairs included
|
4 | |||
| Cat ##10851 | ||||
|---|---|---|---|---|
|
Total reactions
|
384 | |||
|
RNA multiplexing format
|
384 | |||
|
UDI pairs included
|
4 | |||
| Cat ##11051 | ||||
|---|---|---|---|---|
|
Total reactions
|
||||
|
RNA multiplexing format
|
384 | |||
|
UDI pairs included
|
4 | |||
Optimized lysis buffer for complete lysis and efficient reverse transcription.
Compatible with DRUG-seq library prep kits.

Compatible with the MERCURIUS™ product line.
12 UDI pairs.
Flexible dual indexing solutions.



Without pre-amplification, leading to higher mapping and gene detection rates.

Number of samples:
360
Reads per sample in demo dataset:
10'000 reads
To have access to the deep-sequenced dataset (31 GB reads per sample) contact us.
Demo dataset file size:
217 MB
Number of samples:
24
Reads per sample in demo dataset:
10'000 reads
To have access to the deep-sequenced dataset (7.3 M reads per sample) contact us.
Demo dataset file size:
13.3 MB
Number of samples:
24
Reads per sample in demo dataset:
10'000 reads
To have access to the deep-sequenced dataset (7.1 M reads per sample) contact us.
Demo dataset file size:
13.6 MB

Receive email updates on our latest products and services, news and event updates and more. No ads, no spam.