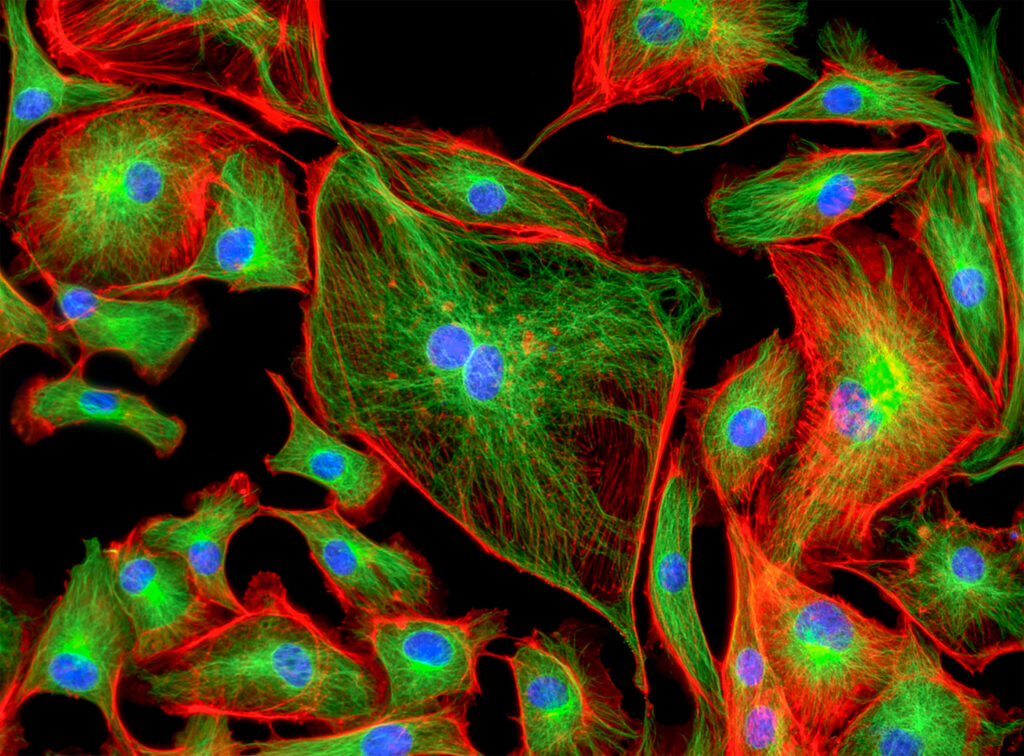
High-content screening is a powerful quantitative image-based approach that has transformed drug discovery, from target identification and primary compound screening to mechanism-of-action studies and in vitro toxicology.
Since the term “high-content screening” was first coined almost 30 years ago, the approach has evolved into an integral component of drug discovery and development, fueled by advances in cellular models, automation, microscopy, and data analysis. High-content screening has significantly impacted the pharmaceutical industry and academia alike and will undoubtedly continue to do so into the future.
In this article, we provide you with a broad overview of high-content screening, its strengths and weaknesses, and some example use cases so you can evaluate how high-content screening might benefit your study.
What is high-content screening?
High-content screening typically refers to the high-throughput image-based assessment of the effects of hundreds to tens of thousands of chemical or genetic perturbations on cellular phenotypes, often at the single-cell level (Fraietta and Gasparri 2016).
Researchers use high-content screening to gather a body of robust information-rich data from complex biological systems, providing a more thorough understanding of cellular responses to potential drug candidates that informs downstream prioritization decisions. High-content screening was initially developed to ease bottlenecks at the target validation, primary screening, and candidate optimization stages in the drug development pipeline (Fig. 1) (Giuliano et al., 1997).
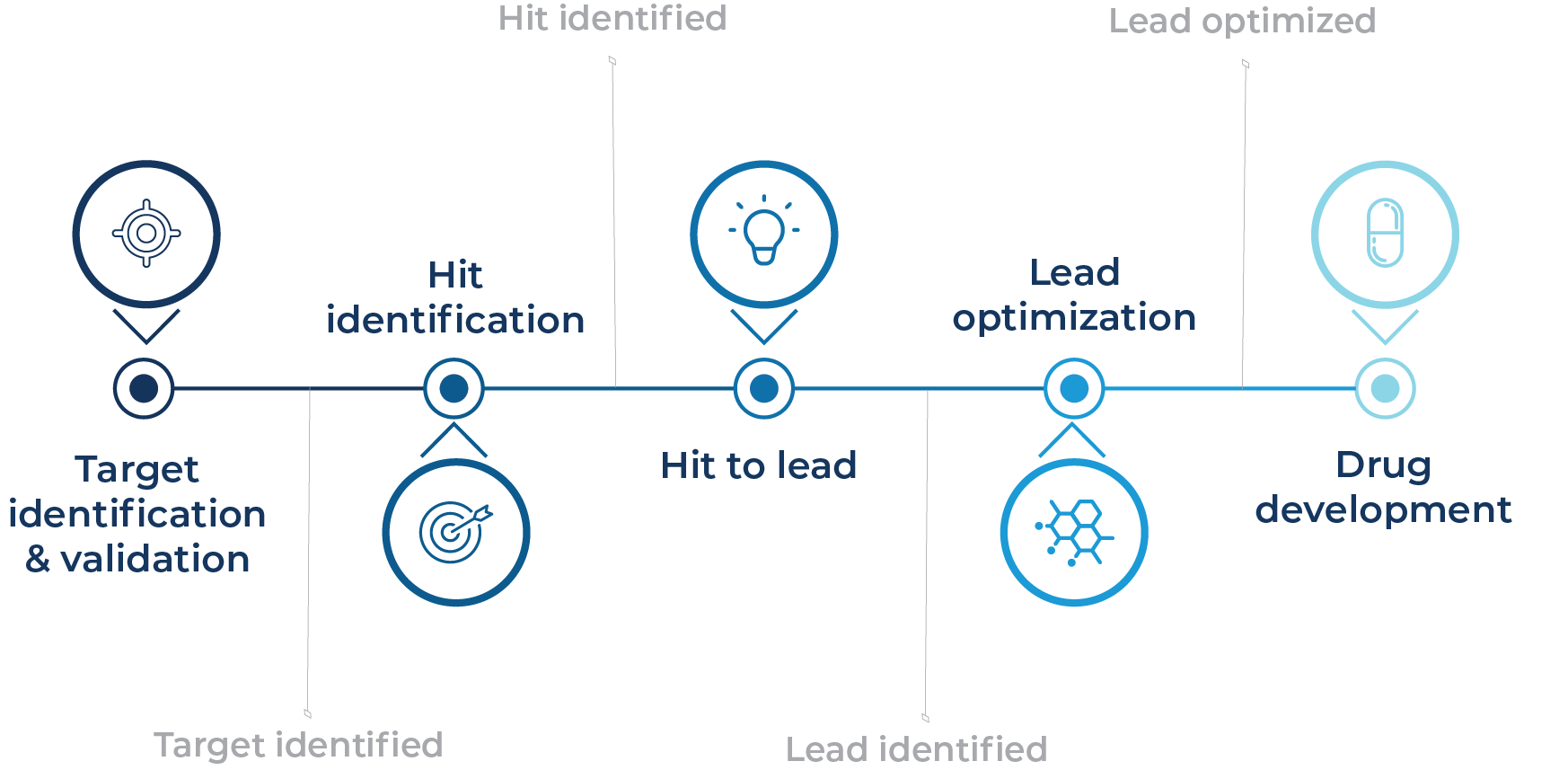
Fig. 1 – The use of high-content screening in the preclinical drug development pipeline
The modern development of powerful but affordable high-content screening platforms, standardized high-content screening approaches like Cell Painting, and high-quality reference image datasets like the JUMP-Cell Painting Gallery continue to positively impact drug discovery and development pipelines (Bray et al., 2016; Chandrasekaran et al., 2023). Integrating advanced imaging microscopes with multiwell plate handling robotics enables high-content imaging to be performed at scale, allowing users to map the morphological effects of vast amounts of cellular perturbations to inform potential mechanisms of action, drug candidates, and toxicology.
While high-content screening can also include proteomic approaches, label-free assays, or flow cytometry, we’ll keep the focus on image-based assays here.
The core components of high-content screening
1. Biological samples
Researchers use high-content screens to assess the effects of drugs on diverse types of samples representing specific disease models or cellular processes, depending on their research question. Samples could include cancer cell lines, primary patient-derived cells, induced pluripotent stem cells, or tissue samples, among many others.
While high-content screening excels for 2D cellular models, there’s an increasing shift toward 3D spheroid or organoid models as they represent more physiologically relevant cellular structures, microenvironments, and cell-cell interactions, all of which could be disrupted by drug treatment or genetic perturbations for target identification (Lampart et al., 2023).
Researchers have now largely finessed the generation of self-organized, multicellular organoids of diverse human tissues like the brain, retina, thyroid, gut, lung, liver, pancreas, and kidneys, and even patient-derived organoids. However, high-content screening with organoids remains tricky due to the scale of multidimensional image datasets. These can be challenging and time-consuming to acquire and analyze, especially for live imaging experiments tracking drug effects over time (Lampart et al., 2023).
2. Staining
Once researchers have found their desired cellular model, fluorescent dyes, molecular probes, antibodies, reporter genes, or genetically tagged proteins are used to label specific cellular structures, such as nuclei, cytoskeleton, or different organelles. Staining patterns can inform on any number of cellular functions like cell cycle status, cellular and nuclear morphology, adhesion, cell death, protein aggregation, etc.
For instance, Cell Painting employs six fluorescent dyes to label eight subcellular components that aid in interpreting hundreds to thousands of morphological features, including size, shape, texture, and intensity. These features are then used to establish morphological profiles to assess how the cellular phenotype changes in response to drug treatment.
3. Imaging and data analysis
Advances in high-content screening wouldn’t have been possible without advances in both automated imaging and image analysis technologies. One of the pioneers of high-content screening, Cellomics Inc., developed the ArrayScan in 1997. It was the first fully integrated platform for high-content screening and paved the way for subsequent platforms that provided end-to-end hardware and software solutions to automatically acquire images, then process, analyze, archive, and visualize them to inform decision making. Today’s platforms can now provide spatial resolution in X, Y, and Z dimensions, suitable for more physiologically relevant 3D spheroid and organoid models.
For data analysis, open source and commercial image analysis software like CellProfiler allows users to create bespoke algorithms for complex phenotype quantification (Stirling et al., 2021). Standard pipelines include image quality control and correction, cell segmentation, cell feature extraction, and batch effect correction. However, recent advances in artificial intelligence and machine learning models are extracting yet more data from images, especially for live cell imaging screens. They will likely provide turnkey acquisition and analysis, with integrated interpretation to further accelerate drug discovery pipelines (Carreras-Puigvert and Spjuth 2024).
High-content screening success stories
The impact of high-content screening on both the pharmaceutical industry and academia alike cannot be overstated. From 1999 to 2008, most first-in-class drugs approved by the US Food and Drug Administration (FDA) were discovered through phenotypic screening (Swinney and Anthony 2011).
Industry groups overwhelmingly classify high-content screening as a current or near-term game-changer, especially for predictive toxicology, as approximately 79% of phase two failures are attributed to safety and efficacy (Dowden and Munro 2019; Pognan et al., 2023).
For instance, one recent study integrated all of the technological advances mentioned above and performed a high-content screen of 1280 bioactive compounds on human iPSC-derived cardiomyocytes, followed by deep learning to identify potential cardiotoxic compounds early in the drug discovery process (Grafton et al., 2021). A single-parameter score was generated by the deep learning model to quantify the cardiotoxic potential of each compound, dramatically increasing assay speed and removing any user biases in interpretation.
The model successfully identified compounds with established cardiotoxic profiles, including DNA intercalators, ion channel blockers, and kinase inhibitors. As around one-third of drugs are withdrawn due to cardiotoxicity safety concerns alone, the information provided by this type of high-content screen could potentially reduce late-stage drug development failures and de-risk early-stage drug discovery (Weaver and Valentin 2019).
Benefits and challenges of high-content screening
The benefits of high-content screening are clear. It provides the pharmaceutical industry with a robust method to reduce the costly, heavy attrition rate of drugs late in the pipeline by detecting on- or off-target effects, toxicological impacts, or unforeseen mechanisms of action early in the pipeline.
Like next-generation sequencing approaches, automated high-content screening contributes to “hypothesis-free discovery” that complements more traditional hypothesis-driven research questions, while removing user biases that hinder traditional microscopy approaches. The significant gains in efficiency and accelerated discovery of new potential therapeutic targets, compounds, and early toxicity prediction are major benefits for the pharmaceutical industry.
One challenge is the initial cost of the equipment necessary, but for drug discovery, the power of high-content screening to inform on go/no-go therapeutics early on likely rapidly negates initial infrastructure investments by reducing dreaded late-stage failures.
Another challenge is that, while there is a gradual shift to physiological 3D models like organoids or systems assembloids, many microscope systems are too slow for high-throughput screening in this setting. The amount of data gathered is too vast and challenging to analyze, especially for live-cell experiments where the response of organoids to drugs is monitored in real-time. Swift advances in hardware and AI-based analysis models are helping overcome this issue and are set to revolutionize high-content screening in the not-so-distant future (Carreras-Puigvert, J. and Spjuth 2024).
Similarly, due to microscopy limitations, most studies still rely on relatively few cellular markers. Ideally, it would be highly beneficial to multiplex as many labels as possible, but users are commonly restricted to only four or five colors owing to limited laser inclusion and associated peaks of absorption and emissions from labels. This is especially problematic for precious patient samples like tumor biopsies, where researchers aim to include as many markers as possible to maximize sample usage and the data insights gained.
The multimodal future
The next era of high-content screening looks set to include multimodal data, where imaging technologies are combined with numerous omics approaches. This advancement is driven by the evolution of high-content screening in parallel with single-cell technologies, whereby image-based single-cell phenotypic classification is immediately followed by collecting single cells for transcriptomics and proteomics (Way et al., 2023).
New platforms are gradually incorporating these features to provide a more comprehensive overview of the effects of perturbations on diverse cellular models. The early use of microfluidic-based labs-on-chips for high-content screening and multiomics is also gaining traction as it overcomes a key bottleneck in sample throughput caused by multiwell plates. Microfluidic devices aim to boost the throughput of experiments beyond what was possible when restricted to a set number of wells (Liu et al., 2023).
Overall, integrating multimodal technologies in high-content screening will undoubtedly play an essential role in further de-risking drug discovery and development pipelines by providing more comprehensive insights into the cellular effects of drug and genetic perturbations than ever before.
To find out more, get in touch with us.
References
- Bray, M.A., et al. Cell Painting, a high-content image-based assay for morphological profiling using multiplexed fluorescent dyes. Nature Protocols, 11(9), pp.1757-1774.
- Carreras-Puigvert, J. and Spjuth, O., 2024. Artificial intelligence for high content imaging in drug discovery. Current opinion in structural biology, 87, p.102842.
- Chandrasekaran, S.N., et al. JUMP Cell Painting dataset: morphological impact of 136,000 chemical and genetic perturbations. BioRxiv, pp.2023-03.
- Dowden, H. and Munro, J., 2019. Trends in clinical success rates and therapeutic focus. Nat Rev Drug Discov, 18(7), pp.495-496.
- Fraietta, I. and Gasparri, F., 2016. The development of high-content screening (HCS) technology and its importance to drug discovery. Expert opinion on drug discovery, 11(5), pp.501-514.
- Giuliano, K.A., et al. High-content screening: a new approach to easing key bottlenecks in the drug discovery process. SLAS Discovery, 2(4), pp.249-259.
- Grafton, F., et al. 2021. Deep learning detects cardiotoxicity in a high-content screen with induced pluripotent stem cell-derived cardiomyocytes. Elife, 10, p.e68714.
- Lampart, F.L., Iber, D. and Doumpas, N., 2023. Organoids in high-throughput and high-content screenings. Frontiers in Chemical Engineering, 5, p.1120348.
- Liu, W., et al. The latest advances in high content screening in microfluidic devices. Expert Opinion on Drug Discovery, 18(7), pp.781-795.
- Pognan, F., et al. The evolving role of investigative toxicology in the pharmaceutical industry. Nature reviews drug discovery, 22(4), pp.317-335.
- Stirling, D.R., et al. CellProfiler 4: improvements in speed, utility, and usability. BMC bioinformatics, 22, pp.1-11.
- Swinney, D.C. and Anthony, J., 2011. How were new medicines discovered?. Nature reviews Drug discovery, 10(7), pp.507-519.
- Way, G.P., et al. Evolution and impact of high content imaging. Slas Discovery, 28(7), pp.292-305.
- Weaver, R.J. and Valentin, J.P., 2019. Today’s challenges to de-risk and predict drug safety in human “mind-the-gap”. Toxicological Sciences, 167(2), pp.307-321.