
DRUG-seq, first published in 2018, has transformed how pharmaceutical, cosmetics, agritech, and AI drug discovery companies screen compounds for on- and off-target effects, mechanisms of action, drug repurposing, and toxicology (1, 2). By moving beyond narrow gene panels and their associated biases toward scalable and affordable transcriptome-wide data, DRUG-seq looks set to improve decision-making capabilities, strengthen early pipelines, and boost compound safety and success rates in the clinic.
But ambitious, high-throughput screening projects demand automation, consistency, and robustness across diverse experimental conditions and sample types. In some instances, achieving this by implementing the published open-source DRUG-seq protocol in-house can be challenging, time-consuming, and costly.
In this article, we compare the published version of DRUG-seq with optimized MERCURIUS™ DRUG-seq from Alithea Genomics, highlight key differences, and explain where the commercialized version delivers added value, especially for labs aiming to generate robust, unbiased transcriptomic data at scale without protocol implementation and optimization bottlenecks.
Quick Answer: What’s the Difference Between Published DRUG-seq and MERCURIUS™ DRUG-seq?
Published DRUG-seq is an open-source, bulk 3’ mRNA-seq method designed for cost-effective, high-throughput transcriptomic screening, but it requires in-house protocol optimization, custom sequencing primers, and has lower library efficiency.
MERCURIUS™ DRUG-seq is Alithea Genomics’ optimized, commercialized implementation of DRUG-seq that removes protocol bottlenecks by using standard Illumina primers, improving library efficiency, reducing hands-on time by ~2 days, and offering plug-and-play scalability for large screening campaigns.
Published DRUG-seq vs. MERCURIUS™ DRUG-seq at a Glance
Before diving into specifics, here’s a quick overview of how the published version of DRUG-seq compares to MERCURIUS™ DRUG-seq from Alithea Genomics (Table 1).
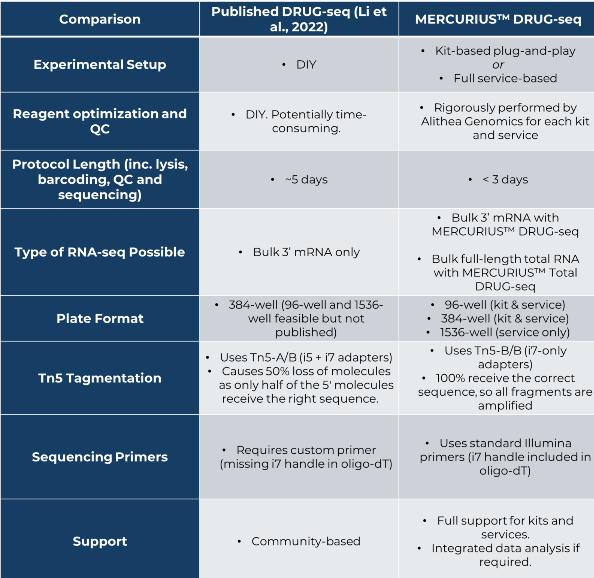
Table 1. Comparison of key features of published DRUG-seq and MERCURIUS™ DRUG-seq
How Are Published DRUG-seq and MERCURIUS™ DRUG-seq Similar?
Standard RNA-seq methods are inherently expensive and struggle to meet the scalability required for high-throughput screening applications. Users must perform tedious library preparation for each sample individually and sequence relatively deeply with at least 15 million reads per sample to detect ~20,000 genes. This makes it costly, time-consuming, and ultimately unfeasible to assess thousands of samples.
In contrast, published DRUG-seq and Alithea’s commercialized version, MERCURIUS™ DRUG-seq, were both specifically developed to make cost-effective and time-efficient high-throughput transcriptomic screening possible. Both technologies enable bulk 3’ mRNA transcriptome-wide readouts across thousands of conditions at low cost.
Published DRUG-seq and MERCURIUS™ DRUG-seq are similar as they:
- Use oligo-dT priming to capture mRNA
- Encode sample identity via barcoded primers
- Include unique molecular identifiers to tag mRNA molecules for PCR artifact detection
- Perform reverse transcription in 96- or 384-well plates (1536-well also available as a service from Alithea)
- Pool samples into one tube early to reduce handling and cost
- Are designed for automation in high-throughput screening workflows
- Detect the expression of 15,000 genes at sequencing depths of less than five million reads per sample
Want to explore some real-world MERCURIUS™ DRUG-seq data? Download our MERCURIUS™ DRUG-seq demo datasets from Hap1, HepG2, and HeLa cells and assess the sensitivity, reproducibility, and gene detection capabilities for yourself.
What Are the Key Differences Between Published DRUG-seq and MERCURIUS™ DRUG-seq?
Despite numerous protocol similarities, MERCURIUS™ DRUG-seq offers several key improvements that enhance ease of use, reduce hands-on time, and streamline the overall workflow.
MERCURIUS™ DRUG-seq is Easier to Deploy
While the data generation capacity of both versions of DRUG-seq is impressive, the published protocol might not always be suitable for laboratories unfamiliar with transcriptomic technologies or that lack the bandwidth to perform the extensive method validation and optimization required before incorporation into their high-throughput screening pipeline.
If establishing the published DRUG-seq protocol from scratch, be prepared for:
- Protocol optimization burden: Optimizing reagents and handling complex, barcoded primers and multiple enzymatic steps could lead to both inter- and intra-batch variability that compounds for large or ultra-large screens.
- Limited support: As an open-source protocol, troubleshooting and scalability fall on the user with limited established support, making it challenging to work out where things went wrong.
In contrast, MERCURIUS™ DRUG-seq kits and services are rigorously optimized, quality-controlled, and come with full support, from experimental design guidance to full data analysis if required.
Technical Improvements of MERCURIUS™ DRUG-seq vs Published DRUG-seq
Both iterations of DRUG-seq employ fundamentally similar stages, like sample barcoding and early sample pooling.
However, the published DRUG-seq protocol suffers from some technological quirks that Alithea’s MERCURIUS™ DRUG-seq now overcomes. You can find the MERCURIUS™ DRUG-seq workflow here for an exact breakdown of stages.
Technological challenges of published DRUG-seq overcome by MERCURIUS™ DRUG-seq:
- Published DRUG-seq needs custom sequencing primers
The barcoded oligo-dT primer used during reverse transcription in published DRUG-seq lacks the i7 priming site required for standard Illumina sequencing. As a result, the cDNA generated cannot be read using standard Illumina sequencing primers, and a custom primer must be supplied to initiate Read 2.
In contrast, MERCURIUS™ DRUG-seq purposefully includes the i7 PCR handle, making it instantly compatible with off-the-shelf Illumina sequencing reagents for a more streamlined workflow that doesn’t require custom primers.
- ~50% of tagmented fragments are unusable due to PCR suppression effects in published DRUG-seq
Both protocols use Tn5 transposase to fragment cDNA and introduce adapter sequences for PCR amplification during tagmentation. The use of unique dual indexing (UDI) enables multiplexing of multiple sequencing libraries on one flow cell, reducing costs while maximizing data output per sample.
Published DRUG-seq uses Tn5 (Tn5AB) loaded with a mixture of i5 and i7 adapters. These adapters are randomly added to the ends of cDNA fragments upon tagmentation. However, only fragments with an i5 adapter on one end and an i7 adapter on the other can be efficiently amplified during PCR. Fragments with i5–i5 or i7–i7 ends lack the necessary complementarity for primer binding and are lost during amplification due to PCR suppression. This means up to 50% of the library is unusable, ultimately reducing library complexity and efficiency.
MERCURIUS™ DRUG-seq solves this by embedding the i5 PCR handle directly into the oligo-dT primer used in reverse transcription. This ensures all cDNA molecules already have an i5-compatible end from the start. Tagmentation is then performed with Tn5 (Tn5BB) loaded only with i7 adapters. This guarantees that all resulting fragments receive the correct i5–i7 configuration for efficient amplification. This design maximizes library yield and sequencing efficiency.
- Published DRUG-seq is two days slower than MERCURIUS™ DRUG-seq
Published DRUG-seq requires approximately five days from harvesting 384 samples to data analysis. MERCURIUS™ DRUG-seq requires less than three days to achieve this.
- Published DRUG-seq is only available as bulk 3’ mRNA-seq
While published DRUG-seq and MERCURIUS™ DRUG-seq both provide robust gene expression information suited to differential expression analysis and pathway detection, they don’t capture splicing, alternative promoter usage, or transcript isoform activation as they are 3’ mRNA-seq technologies. These transcript features are frequently associated with diseases and responses to compound treatments, so could be important for deciphering mechanisms of action or toxicological effects.
For industries requiring scalable bulk total RNA-seq in their high-throughput transcriptomic screening pipelines, Alithea Genomics has recently launched MERCURIUS™ Total DRUG-seq and MERCURIUS™ Full-Length DRUG-seq to overcome the limitations of 3’ approaches.
Where Have Published DRUG-seq and MERCURIUS™ DRUG-seq Been Used Successfully?
Despite these protocol differences, the overall attributes of published DRUG-seq and MERCURIUS™ DRUG-seq have helped researchers uncover repurposable neuroactive drugs with potent anti-glioblastoma efficacy, contributed to multiomics-based detection of brain-penetrant small-molecule modulators of human microglia, and have led to the discovery of diverse mechanisms of action, established the toxicological effects of compounds, and are helping to train the next generation of AI models (2-6).
The recent launch of the open-source DRUG-seq MoA Box dataset from Novartis showcases the power and scalability of DRUG-seq, as it contains almost 60,000 samples from 52 batches of triplicate 384-well plates (6). The dataset tests 4,343 unique compounds in triplicate at four doses and is intended to help researchers develop new computational analysis methods that require large-scale, unbiased transcriptomic data.
Which DRUG-seq Approach Should You Choose?
Overall, both published DRUG-seq and MERCURIUS™ DRUG-seq from Alithea Genomics enable high-throughput transcriptomic screens at unprecedented resolution and efficient cost per sample. However, MERCURIUS™ DRUG-seq builds upon the biological strengths of published DRUG-seq while removing key technical and operational barriers that limit scalability, reproducibility, and turnaround time in real-world screening pipelines.
Published DRUG-seq is best suited for:
- Academic or method-development labs
- Teams with in-house NGS and protocol optimization expertise
- Users willing to trade time and efficiency for flexibility
MERCURIUS™ DRUG-seq is best suited for:
- Pharma, biotech, cosmetics, and agritech screening teams
- Large or ultra-large compound screens
- Labs prioritizing